最近在研究Key-Value数据库,思考之后打算尝试着重造轮子。目标是做一个高效Key-Value数据库,要实现一个Key-Value数据库本身并不困难,但是要做到存取、查询效率足够高的话,还是要靠背后的数据结构。在一番搜索之后,暂时决定用Ternary Search Tree来实现试试。
简单说明一下Ternary Search Tree,它的结构十分简单,每个结点储存一个字符,还有三个指针,分别对应下一个字符与当前字符的大小关系——小于、等于、大于。
下面是一个典型的三分搜索树的结点的结构
typedef struct tsnode { char c; struct tsnode * le, * eq, * gt; } tsnode, * tstree;
查找/插入的字符小于当前字符就转向左子树,大于则转向右子树。当等于的时候,考虑两种情况,一是查找的字符已经是NULL,即需要搜索/插入的字符串已经走到了结尾。如果是插入的话,此时就可以将要插入的字符串的地址赋给当前结点指向等于关系的指针。如果是搜索的话,则可直接返回当前结点指向等于关系的指针(因为我们在插入时将这一指针赋值为了字符串的地址)。
举个例子,我们要想把ABCD、ABCC、BCD、ABD依次插入到一颗Ternary Search Tree的时候,我们经历了如下步骤:
假设我们的插入函数定义为
/** * @brief Insert * * @param tree 要插入到哪一棵树 * @param key 要插入的字符串 * @param offset 用于后面记录当前字符与字符串开头的偏移量,方便递归调用 * * @return Ternary Search Tree */ tstree TernarySearchTree::insert(tstree tree, const char * key, size_t offset = 0);
那么我们的调用如下,
tstree tree = NULL; tree = TernarySearchTree::insert(tree, "ABCD"); tree = TernarySearchTree::insert(tree, "ABCC"); tree = TernarySearchTree::insert(tree, "BCD"); tree = TernarySearchTree::insert(tree, "ABD"); // 接下来就进入到insert函数 TernarySearchTree::insert(tstree tree, const char * key) { // 首先判断传入的tree是否为NULL if (tree == NULL) { // 是的话,则malloc内存 tree = (tstree)malloc(sizeof(tsnode)); // 将这个结点储存的字符赋值为key的第一个字符 tree->c = *key; // 其余三个指针都为NULL tree->le = tree->eq = tree->gt = NULL; } // 接下来比较大小 // (即使传入的时候为NULL,我们也在上面的if中为它申请了内存,并赋了相应的值,这时自然是"相等"的状态) if (*key < tree->c) { // 插入的字符小于当前结点储存的值,转向左子树继续插入 tree->le = tstree_insert(tree->le, key, offset); } else if (*key > tree->c) { // 插入的字符大于当前结点储存的值,转向左子树继续插入 tree->gt = tstree_insert(tree->gt, key, value, offset); } else { // 插入的字符等于当前结点储存的值,判断情况 if (*key != '\0') { // 如果还没到达末尾,说明是有同样的前缀,向中间的子树插入下一个字符的值 tree->eq = tstree_insert(tree->eq, ++key, ++offset); } else { // 如果到达了末尾,那么就把key的地址赋值给当前结点的eq指针 // 如果eq指针已经有值了,说明插入的是一个重复的key, 此时不必strdup if (tree->eq == NULL) { tree->eq = (tstree)strdup(key); } } } }
实际过程如下图

三分搜索树在查找的时候很简单,顺着它的设计思路往下走就行。
/** * @brief Insert * * @param tree 在哪一棵树中查找 * @param key 要查找的字符串 * * @return 是否查询到 */ bool TernarySearchTree::insert(tstree tree, const char * key) { tstree root; root = tree; while (root) { if (*key < root->c) { // 小于则转左树 root = root->le; } else if (*key > root->c) { // 大于则转右树 root = root->gt; } else { // 等于的时候判断情况 if (*key == '\0') { // 查询字符串已经递归走到末尾了 // 意味着找到了 return true; } // 否则只是有相同的前缀 // 需要继续查找下一个 key++; root = root->eq; } } return false; }
那么可以清楚的看出来,三分树的复杂度近似于O(n),不过在最坏情况下顺序插入字符串会退化成一个链表。但是Ternary Search Tree在最坏情况下也会比Binary Search Tree好一些。
那么基本的插入/搜索Key的方法明白,接下来就是放Value了,这个并不麻烦,在结点上增加一个userdata字段就可以。考虑到实际中Value可能普遍比较长,于是采用Google的Snappy库对Value进行压缩,那么为了在数据库GET时能正确解压,还需增加一个字段记录Value压缩后的大小。于是实际使用的结构如下
typedef struct tsnode { char c; struct tsnode * le, * eq, * gt; const char * userdata; size_t len; } tsnode, * tstree;
由于完整的代码与刚才所列举的典型代码差不太多,这里就不写了,已经放在GitHub上了,layerdb
由于现在只是放在内存中,所以就仅仅与STL的map容器测试了一下。
测试一
- 100万条数据
- 随机字符串
- 固定长度
- 长度为4/8/16/24/32/48/64/128/192/256字节
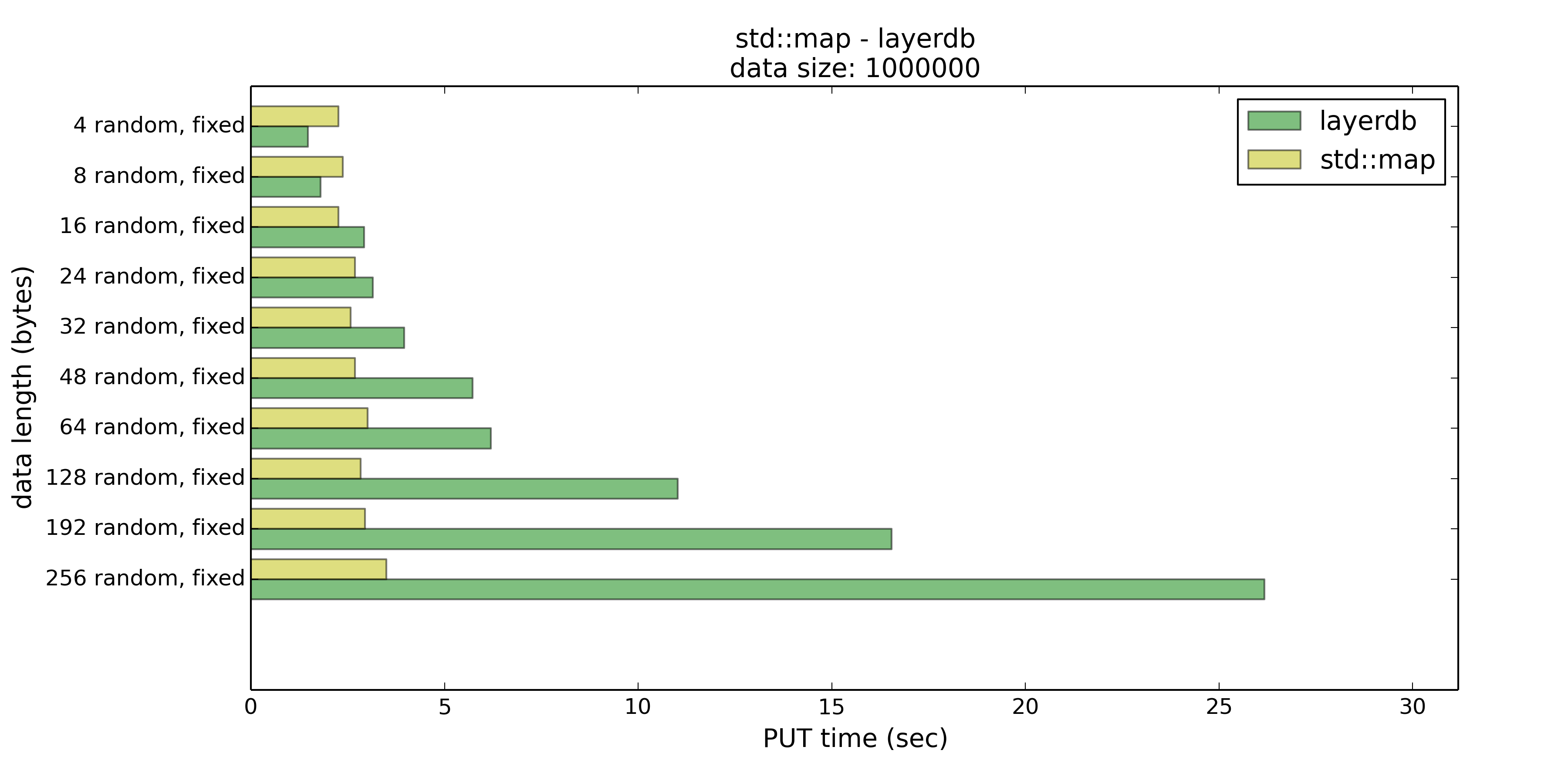
先来看看PUT所用的时间吧
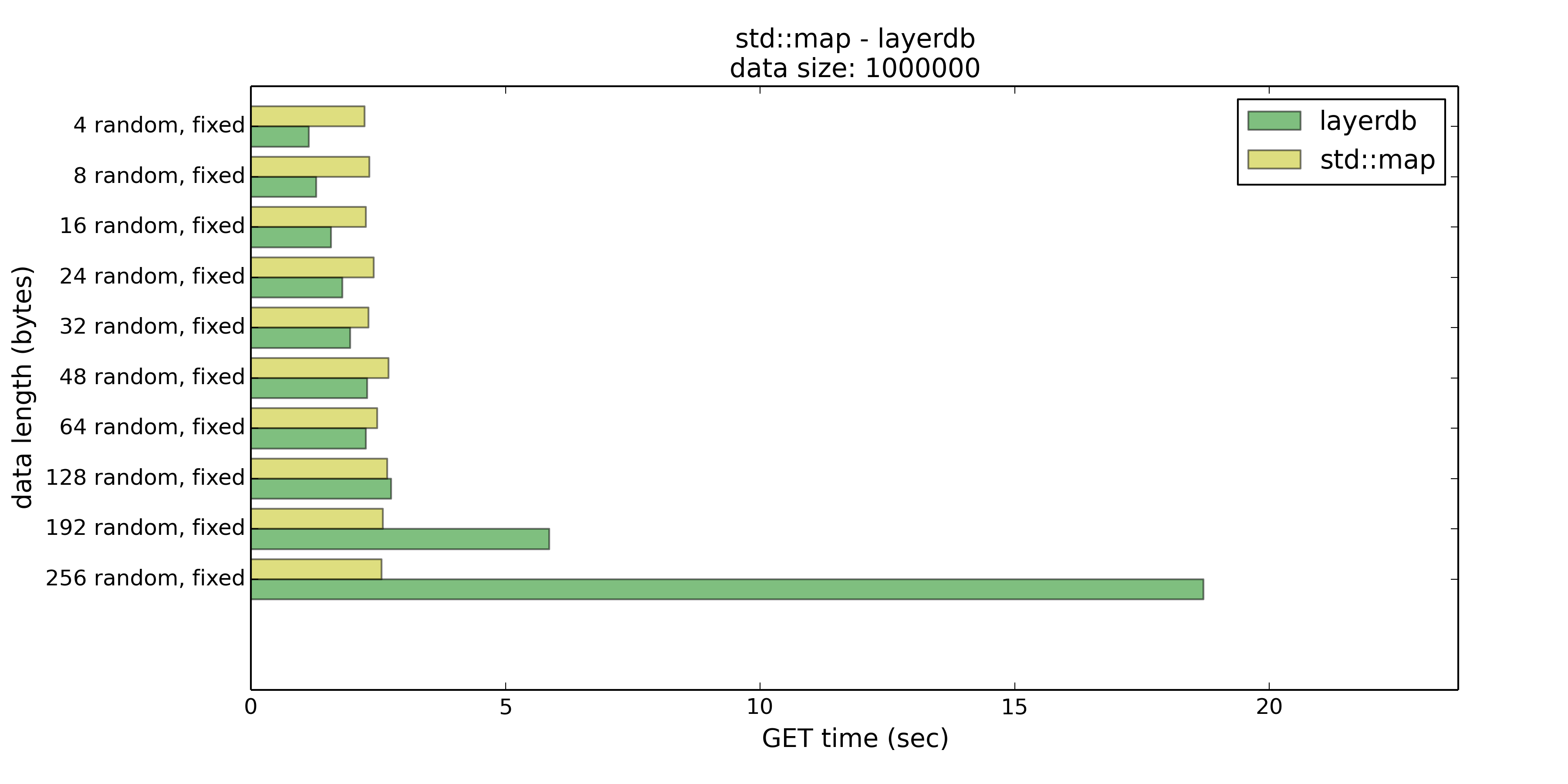
接下来是GET的时间
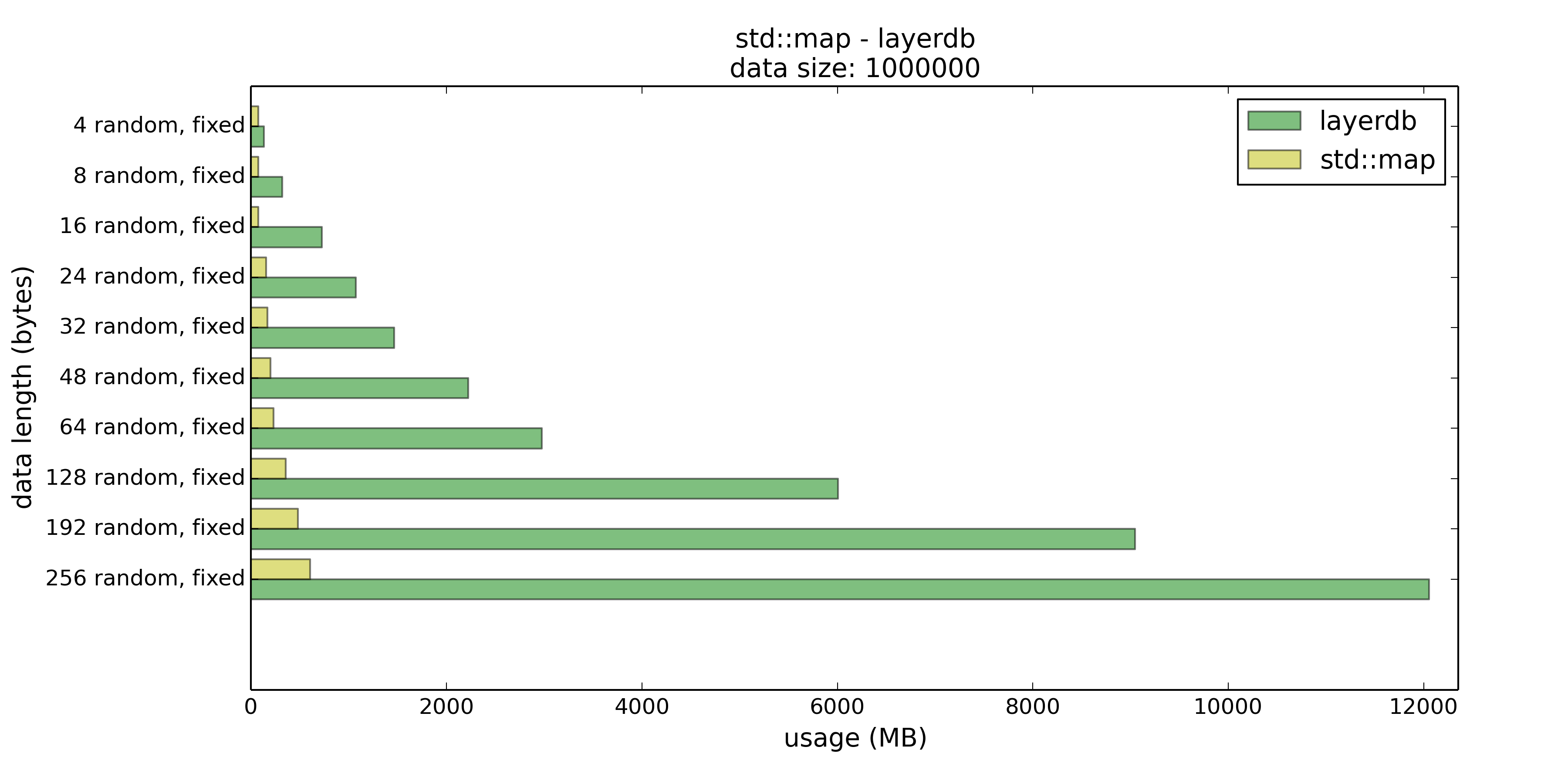
最后是内存使用情况
可以看出,layerdb在种情况下,放入的key长度较小时,layerdb在PUT时,性能略优于std::map,但是这点时间并算不上有多大的优势。在长度达到32字节时,layerdb所用时间已经大幅超过了std::map。
在GET的时候,Key长度在64字节以下表现基本优于std::map,这也是Ternary Search Tree的优势所在。
最令人心疼的就是layerdb的内存使用率了,当然,现在真要比的话,人们是愿意用空间换时间的,但是这……用得太多了……在Key长度超过16字节之后就不忍直视了。
如果能确保放入的Key的长度都在16或者32个字节以内,layerdb比起std::map还是有优势的。否则在此测试的条件下还是选择std::map吧。
从测试一中可以看出,layerdb所使用的Ternary Search Tree在应付较长的Key时显得十分吃力(还吃内存),不过在Key长较小时表现不错,那么下面一个测试的重点就放在长度较小的Key上。
测试二
- 1000万条数据
- 随机字符串
- 随机长度,8/16/24/32字节
- 固定长度,4/8/16/24字节
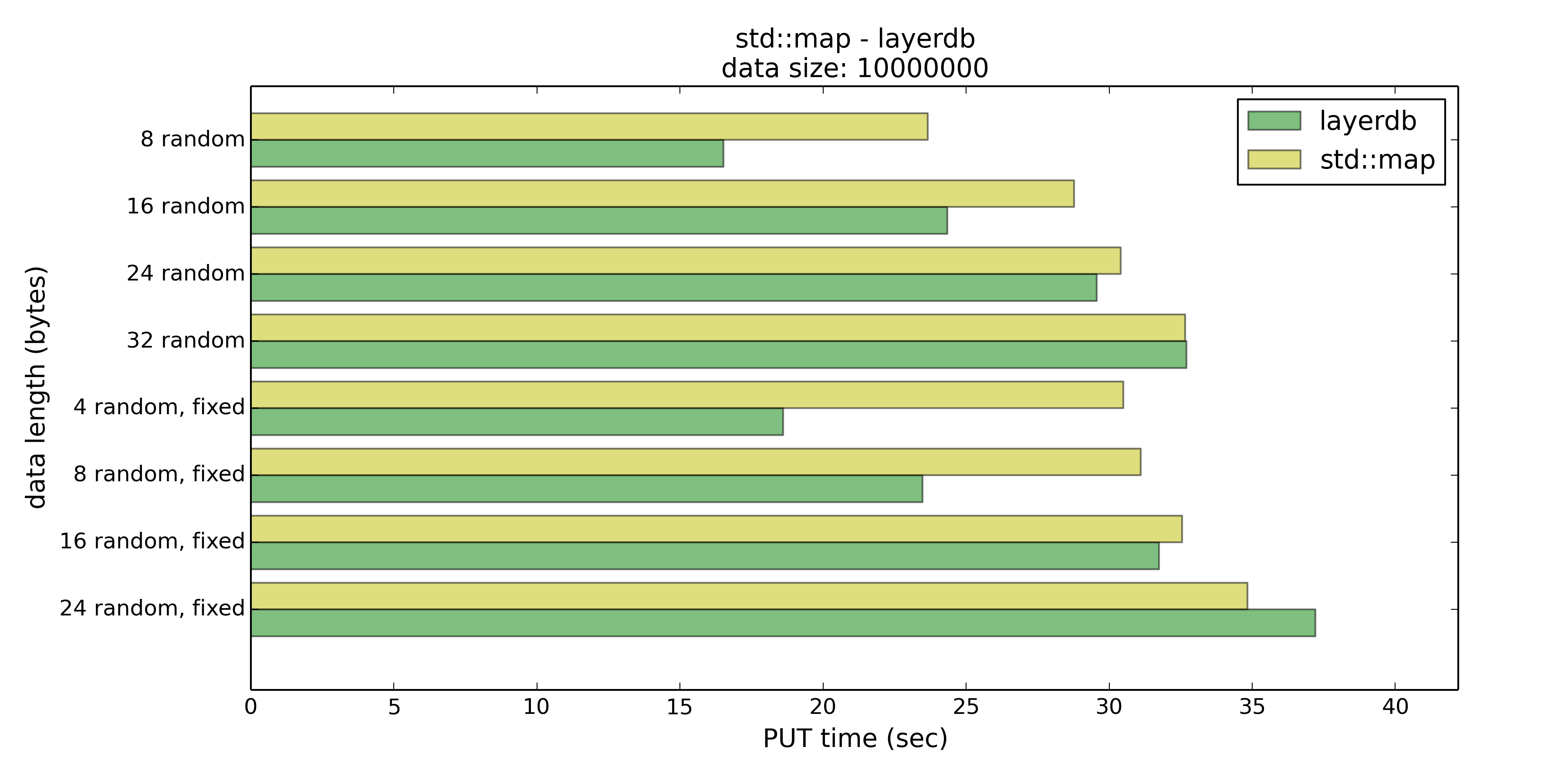
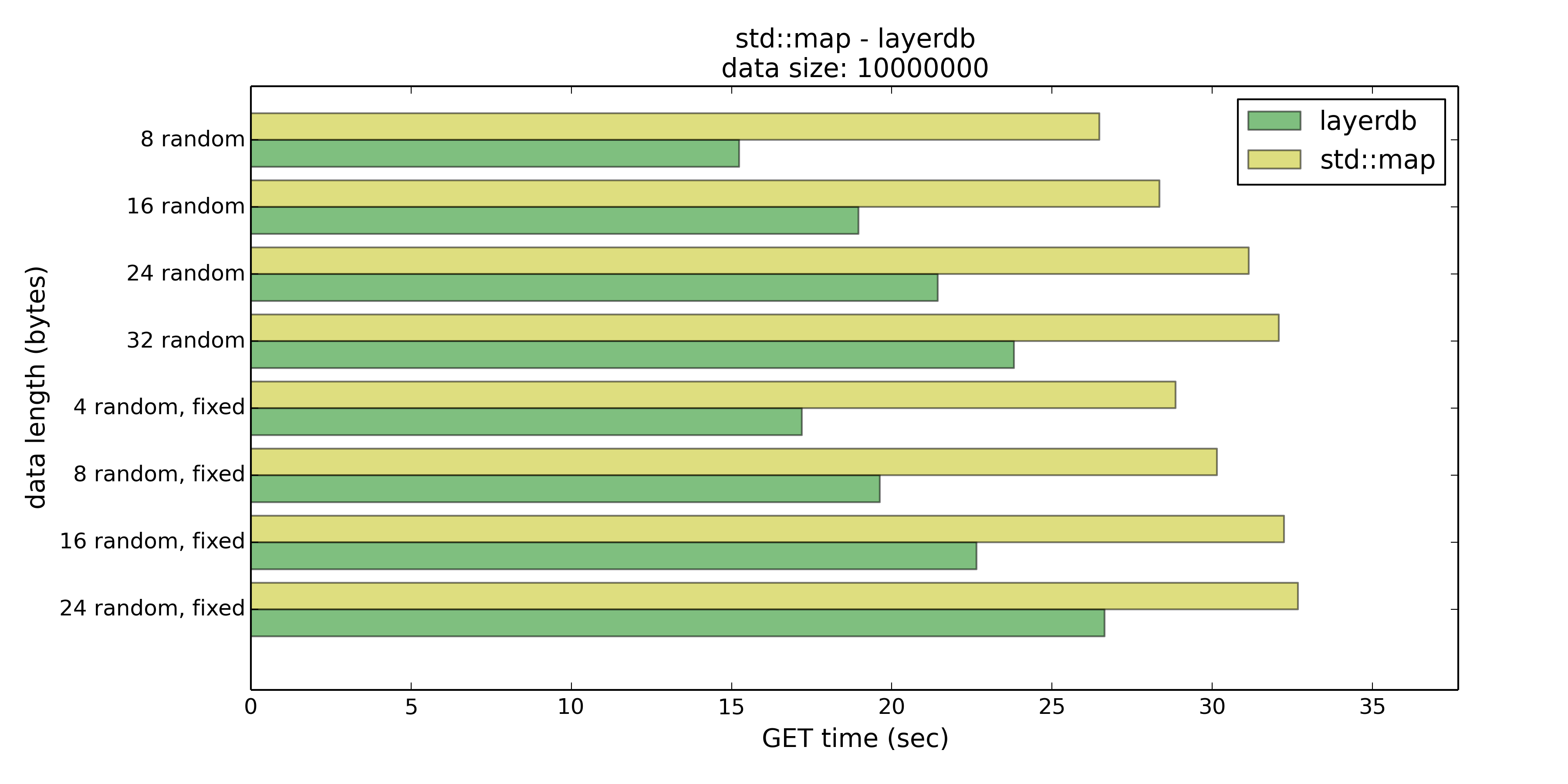
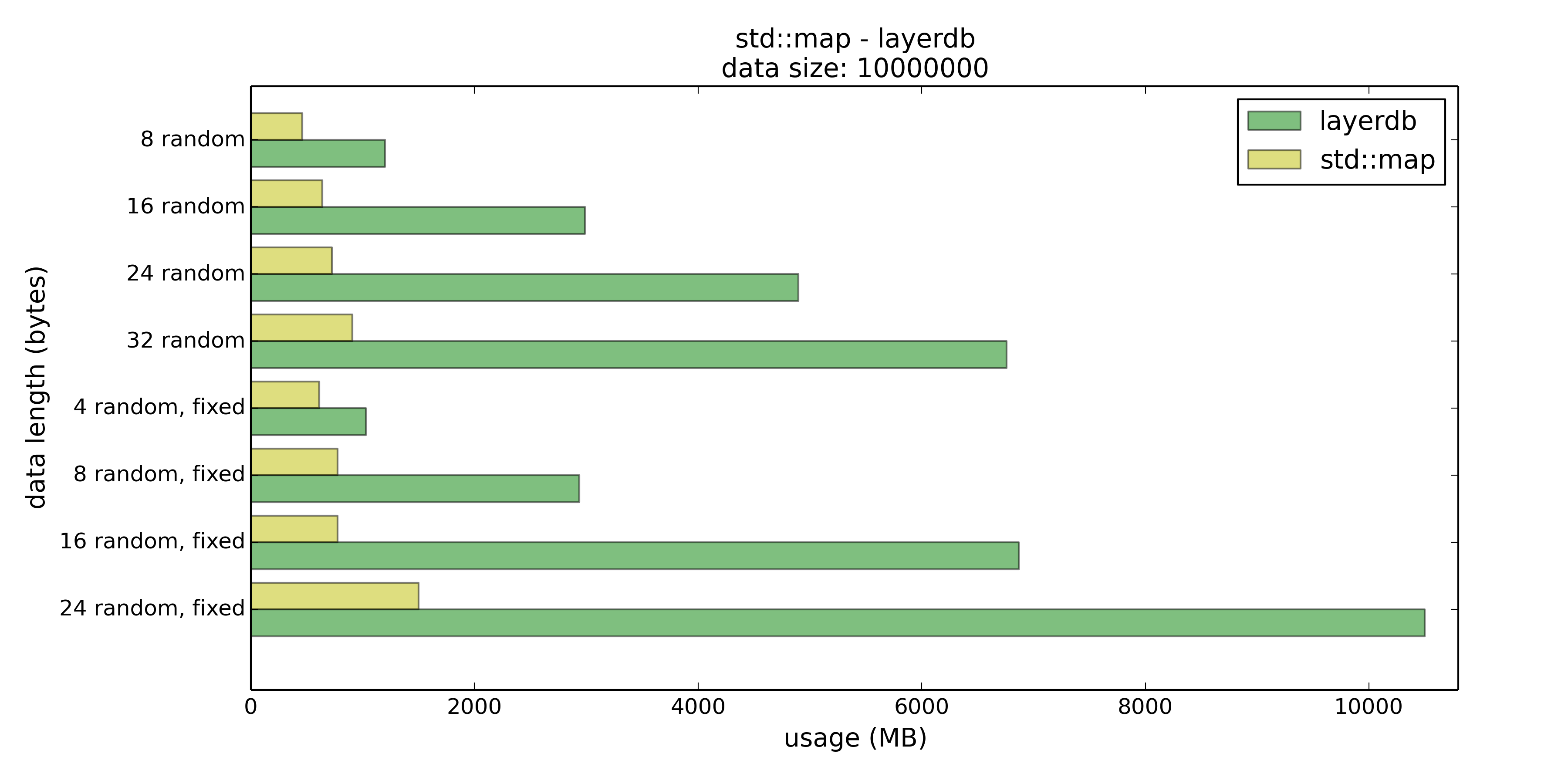
在这个测试中layerdb的表现几乎全面优于std::map,PUT仅在8/16字节长时优势相对明显,不过在GET时layerdb普遍有15%到40%的性能优势。然而这15%到40%的性能优势是通过巨大的空间代价换来的。
那么测试二和测试一的结论差不多,如果Key控制在16字节以下的话,是可以选择layerdb来节约时间的。
那么在更大的数据量、以及Key控制在16字节长度的情况下,到底有多少时间优势呢?
测试三
- 3000万条数据
- 随机字符串
- 随机长度,4/8/16字节
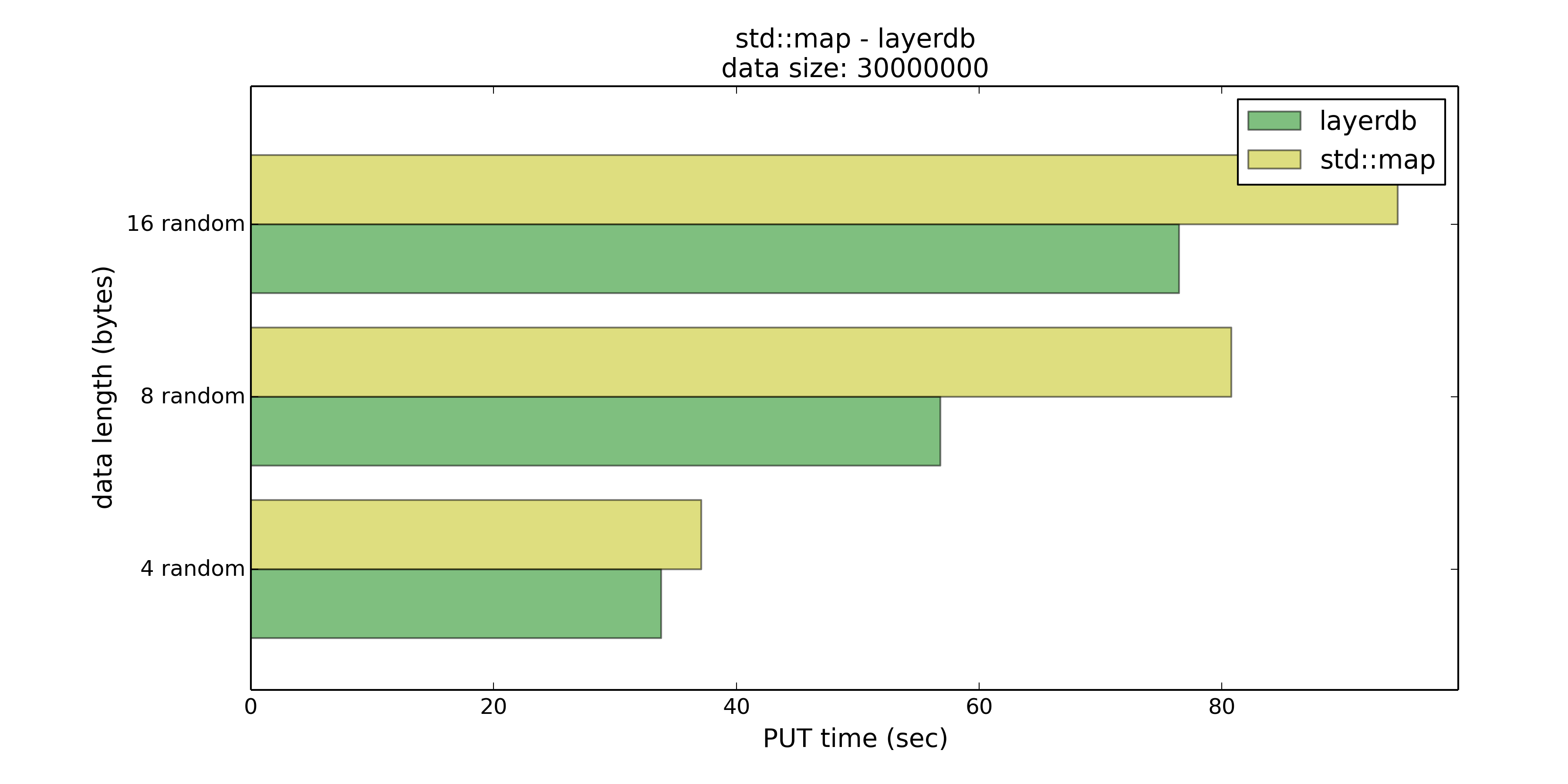
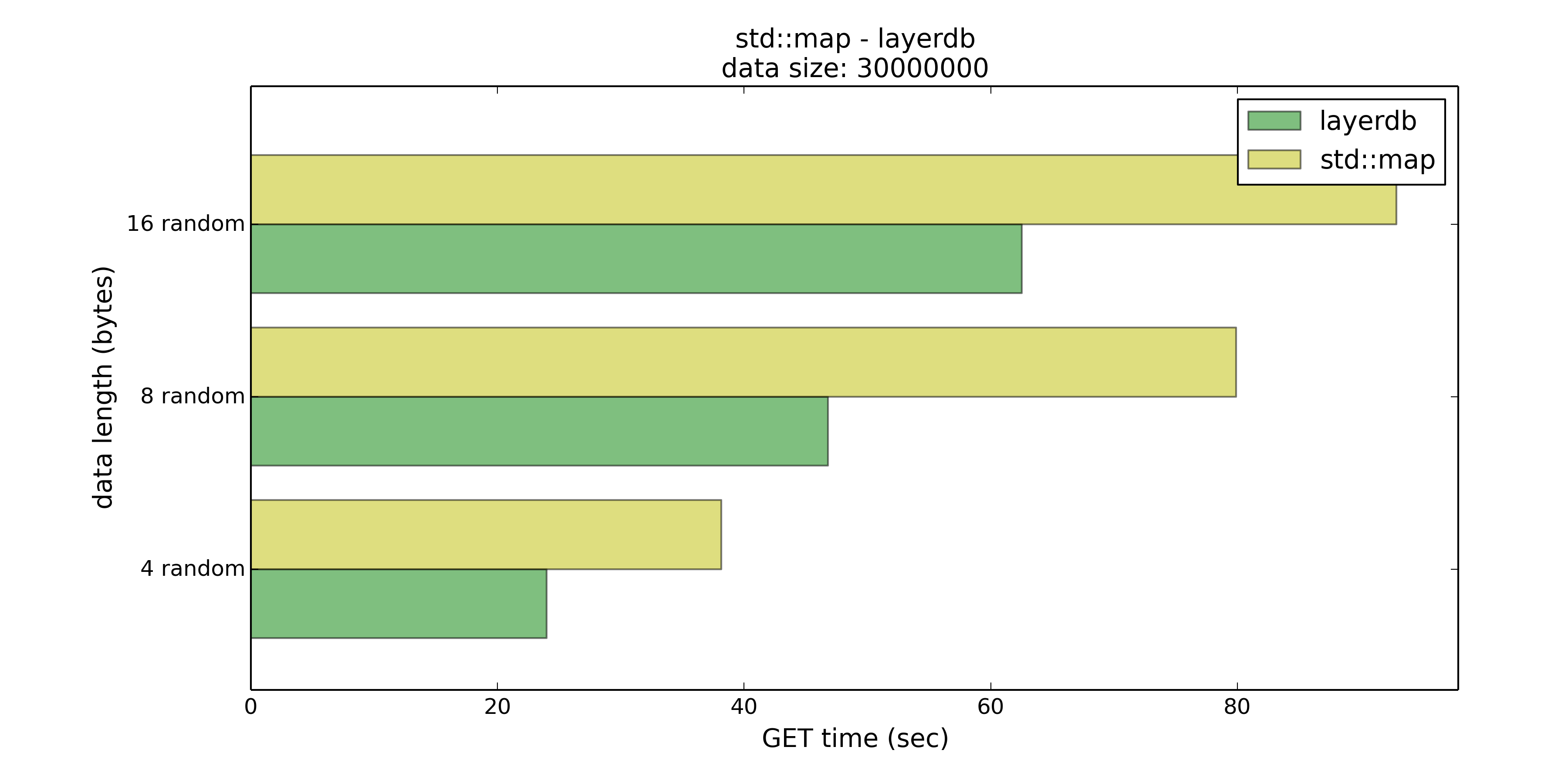
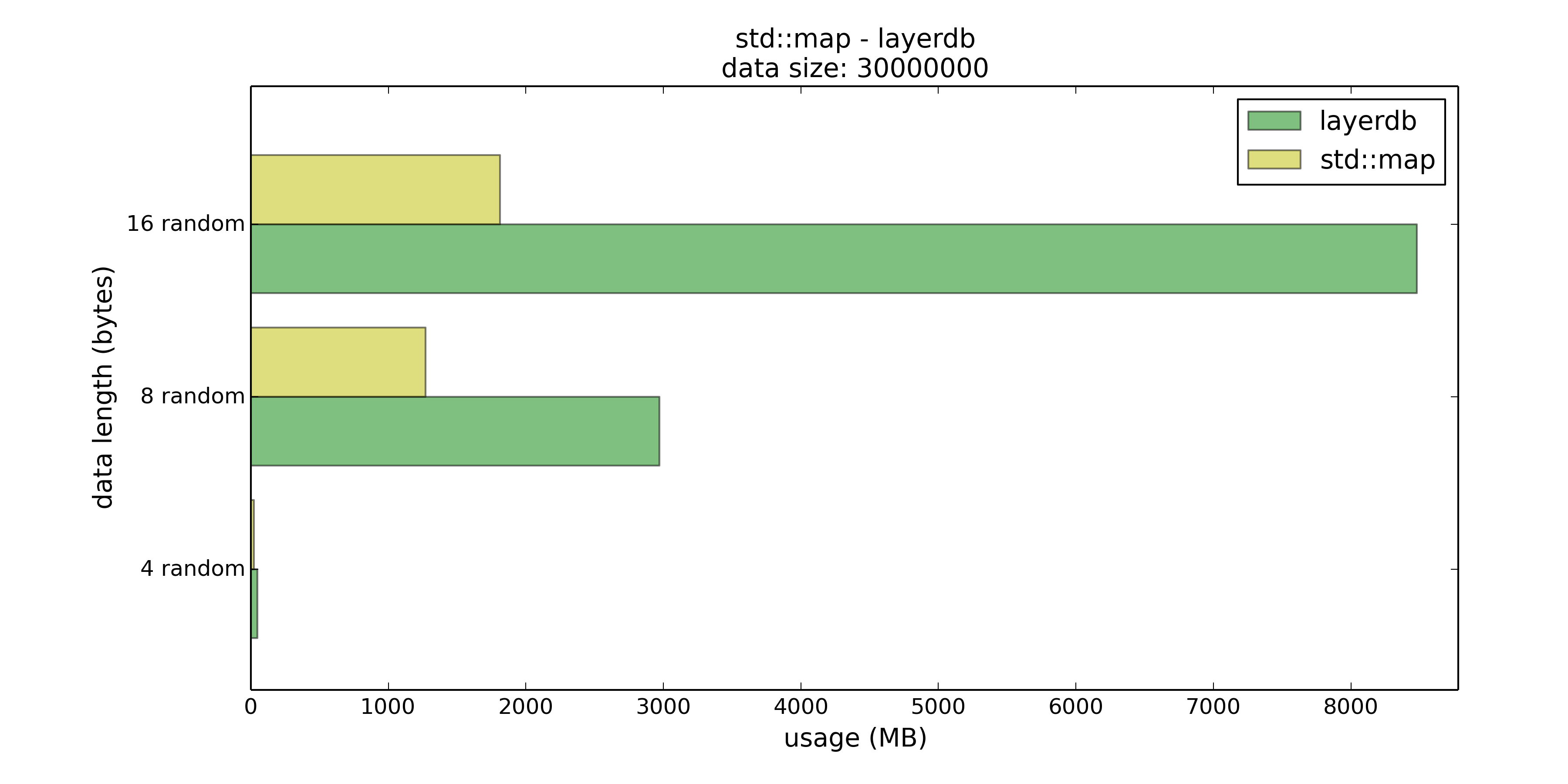
当Key在4字节以内时,layerdb的内存消耗与std::map基本相同,但是在PUT和GET上分别有8%、37%的优势。
当Key长度在8字节以下时,优势上升到29%和41%,内存使用量约为std::map的2.3倍,但是这样的交换或许还是可以接受的。
当Key长度在16字节以下时,优势回落到19%和32%,虽然优势看上去也还是不错,但内存使用已经是std::map的三倍左右了。
最后
直观地讲,对于大量随机数据,Ternary Search Tree的搜索效率在小于32字节时还是很不错的,在超过了这个门槛的时候,内存使用急剧提高,并且搜索效率也不容乐观。
当然,本来也就不能指望一个算法解决所有的问题。或许会修改为在Key长度大于32字节时采用其他数据结构,而在32字节以内就用Ternary Search Tree.
how to handle non-ascii keys?