在看了NTU的AI课程之后,试着用C++来实现了A*搜索算法。它的思想就是Avoid expanding paths that are already expensive.。标准的A*搜索算法描述如下:
给出带权无向图,初始顶点,目标顶点,以及evaulation function。Evalutaion function包括
- g(n):为到达顶点n,当前已有的花费(cost so far to reach n)
- h(n):一个 从任意顶点 到 目标顶点 的估计花费(estimated cost to goal from n)
- f(n):从 初始顶点 到 目标顶点 的估计花费(estimated total cost from the starting node to goal through n)
f(n) = h(n) + g(n)
例如有三个地点A, B, C,它们之间的图如下
A —— B —— C
A —— B权重为30,B —— C权重为40,
A —— C的直线距离为50,但是并没有A——C这条边(即不能直接从A开始,只经过一条边就到达C)
现在,给出初始顶点为A,目标顶点为C,h(n)如下
h(A) = 50
h(B) = 40
h(C) = 0
在一开始,我们将A放入名为froniter的优先队列中,froniter按照f(n)的值升序排序。
那么我们有f(A) = h(A) + g(A)。h(A)是由用户直接给出的,等于50。g(A)是我们为了到达C,已有的花费,在这个例子中,可以理解为已经走过的路程,因为我们是一开始就在A,还没有开始走,所以g(A)为0。于是f(A) = h(A) + g(A) = 50 + 0 = 50
froniter中的数据如下:
| current | from | g(current) | h(current) |
|---|---|---|---|
| A | A | 0 | 50 |
然后我们开始循环,只要froniter不为空,就取出队首的元素。然后从队列中删除它。并且通过一个一维数组visit记录我们是从哪个node到达当前node的。然后我们做goal test,即判断 当前顶点 是否就是我们的 目标顶点,如果是,则退出循环。如果不是,则展开当前顶点。展开当前顶点的操作为:把所有 邻接当前顶点 的 顶点n放入froniter,h(n)由用户给出,g(n)则为g(current_node) + 当前顶点 到 顶点n 的权重。
整个循环的伪代码如下(或者跳到真实实现)
while (!froniter.empty()):
(current, from, g, _) = froniter.top();
froniter.pop();
visit[current] = from;
if (current == goal) break;
else:
for_each node in ajacent_node(current):
froniter.push((node, current, g + weight(from: current, to: node), h(node)));
在这个例子中,froniter的队首为A,我们将有:
visit[A] = A;
A不是目标顶点,展开A;
与A邻接的顶点有B;
将B放入froniter
此时froniter中的数据如下:
| current | from | g(current) | h(current) |
|---|---|---|---|
| B | A | 30 | 40 |
然后因为没有更多的邻接顶点,开始下一轮循环。
froniter的队首为B,
visit[B] = A;
B不是目标顶点,展开B;
与A邻接的顶点有A, C;
将A, C放入froniter
此时froniter中的数据如下:
| current | from | g(current) | h(current) |
|---|---|---|---|
| C | B | 70 | 0 |
| A | B | 60 | 50 |
再次开始下一轮循环,此时
froniter的队首为C,
visit[C] = B;
C是目标顶点,退出循环
那么在退出循环之后,我们只需要逆向访问visit数组,一路回到初始点即可。
from = goal;
stack.push(from);
while (from != initial):
from = visit[from];
stack.push(from);
然后根据需要,既可以直接返回stack,也可以再把stack依次取出,放入queue或者数组。
对NTU AI课程, Week 3, Lecture 2中,计算从古亭到台北车站的最优路径的解
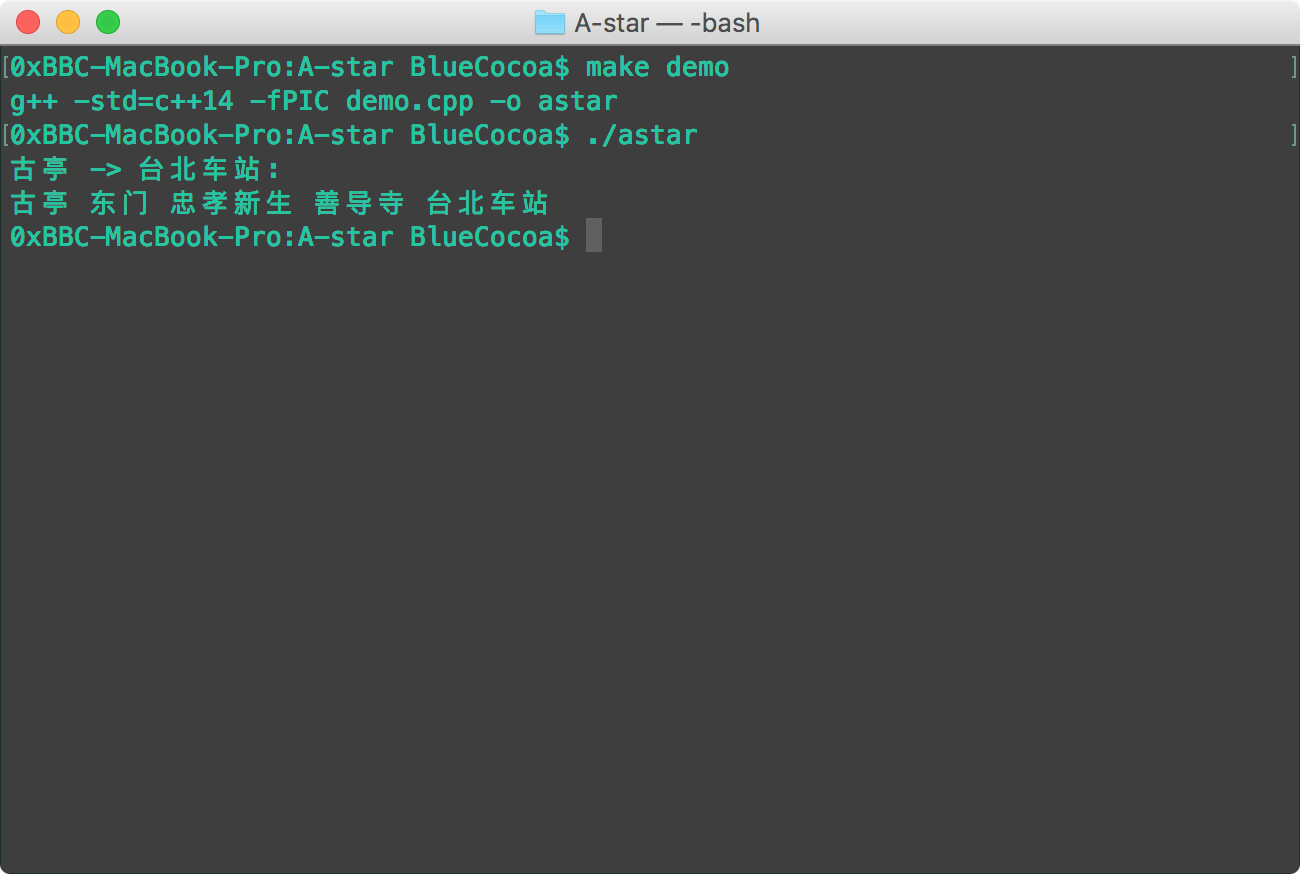
整个A* Search Algorithm如下,(A-star)
#include <stdlib.h> #include <functional> #include <limits> #include <queue> #include <set> #include <stack> #include <tuple> #include <vector> /** * @brief A* Search Algorithm * * @param nodes Number of nodes * @param graph 2-dimension ajacent matrix * @param initial Starting node * @param goal Target node * @param estimated Heuristic function * * @note If estimated function is not provided, A* search is equivalent to uniformed-cost search */ template <typename Weight> std::vector<size_t> Astar(size_t nodes, const Weight ** graph, const size_t initial, const size_t goal, const std::function<Weight(const size_t current)>& estimated = [](const size_t current) -> Weight { return 0; }) { // return an empty std::vector on invaild input if (nodes == 0 || graph == nullptr) return std::vector<size_t>(); // return <initial, goal> if initial equals to goal if (initial == goal) return std::vector<size_t>(initial, goal); // state: current node, via, g(n), h(n) // g(n): cost so far to reach n // h(n): estimated cost to goal from n using state = std::tuple<size_t, size_t, Weight, Weight>; // compare function for std::priority_queue auto cmp = [](const state& a, const state& b) { // (g(a) + h(a)) > (g(b) + h(b)) // a.k.a sort by estimated total cost from initial node to goal through n return ((std::get<2>(a) + std::get<3>(a)) > (std::get<2>(b) + std::get<3>(b))); }; // frontier, increasing order std::priority_queue<state, std::vector<state>, decltype(cmp)> frontier(cmp); // visited node std::set<size_t> visited; // froniter set std::set<size_t> froniter_set; // record trace size_t * visit = (size_t *)malloc(sizeof(size_t) * nodes); // start from initial node frontier.push({initial, initial, 0, estimated(initial)}); froniter_set.emplace(initial); // a flag variable bool found = false; // frontier will be empty if goal is not in our search space while (!frontier.empty()) { // this is least weighted node auto current = frontier.top(); // node number size_t current_node = std::get<0>(current); frontier.pop(); froniter_set.erase(current_node); // record that this node has been visited visited.emplace(current_node); // we go to this node via last size_t from = std::get<1>(current); visit[current_node] = from; // goal test if ((found = (current_node == goal))) { break; } else { // iterate possible node for (size_t to = 0; to < nodes; to++) { // don't stay here // and if node to is reachable from current node if (to != current_node && graph[current_node][to] != std::numeric_limits<Weight>::max() && (visited.find(to) == visited.end())) { // don't go back if (froniter_set.find(to) == froniter_set.end()) { // push this state to frontier frontier.push({to, current_node, std::get<2>(current) + graph[current_node][to], estimated(to)}); froniter_set.emplace(to); } } } } } std::vector<size_t> trace; if (found) { // build trace std::stack<size_t> trace_stack; size_t from = goal; trace_stack.push(from); while (from != initial) { from = visit[from]; trace_stack.push(from); } // move trace into std::vector while (!trace_stack.empty()) { trace.emplace_back(trace_stack.top()); trace_stack.pop(); } } free((void *)visit); return trace; }