最近我所在的一个 GitHub Organization 的网站上搭起了 Mastodon 实例,于是花这几天的时候从一个较为高层的角度分析了 Mastodon,这里并没有深入到最底层的代码。大概还有不少人不了解 Mastodon 这个项目,于是结合 Mastodon 官方的介绍,这里将分析 Mastodon 项目的现状以及对 Mastodon 未来的预测。
- Mastodon 简介
- 监控 Mastodon 实例
- 分类不同类别的 Mastodon 实例
- - 刚刚起步的 Mastodon 实例
- - 小有规模的 Mastodon 实例
- - 中型规模的 Mastodon 实例
- - 大型规模的 Mastodon 实例
- 为差不多中型规模的 Mastodon 实例建模吧
- - 边界花费
- 社交网络的未来形态
Mastodon 简介
那么这里请先让我来十分简要地介绍一下这个项目。根据 Mastodon 在 GitHub 上的简介是这样的:
Mastodon is a free, open-source social network server. A decentralized solution to commercial platforms, it avoids the risks of a single company your communication. Anyone can run Mastodon and participate in the social network seamlessly.
“Mastodon 是一个免费,开源的社交网络服务。一个去中心化的商业平台替代,它避免了某一个公司垄断你的社交。任何人均可以运行自己的 Mastodon 并进行无缝交流。”
言下之意就是在 Mastodon 出现之前,人们普遍使用的社交网络几乎可说都是由商业公司运营的,那么这些商业化的社交平台极有可能让你形成依赖,毕竟你的关注者、你发布的内容都在它们的平台之上。当这种依赖到一定程度之后,你就很难抽身了。而现在有了 Mastodon 之后,任何人都可以独立运行 Mastodon 的实例。一言以蔽之——以分布在世界各地的小节点组成的社交网络取代先前老大哥式的社交平台。
官方发布的 Mastodon 的 Web 界面大概如下,
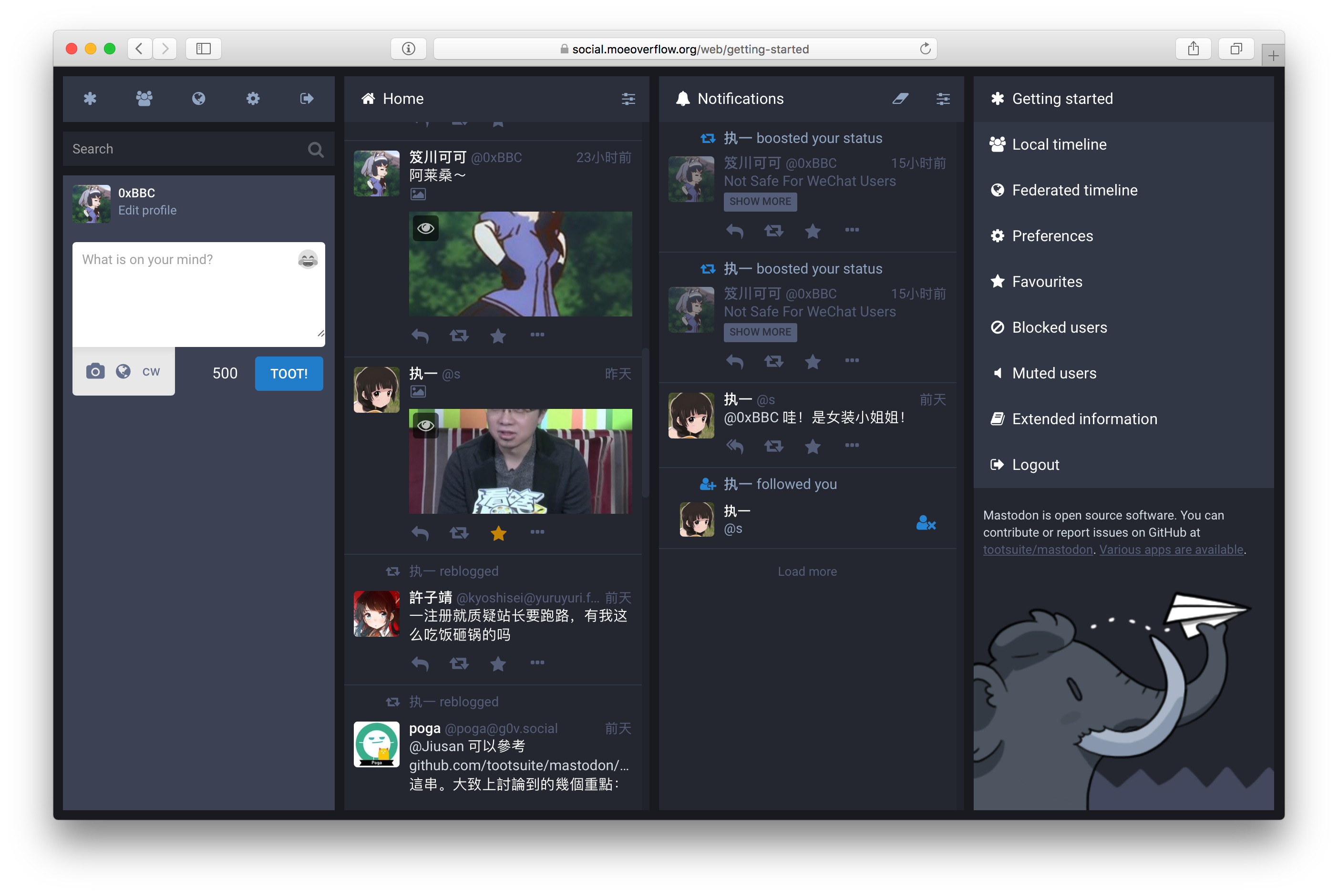
与 TweetDeck 的界面非常相似,内容分区明显,设计上也很不错,现代化的风格与操作。与 Twitter 不同的是,在不同的 Mastodon 实例上需要分别在对应的地方注册,当然注册过程很简单,提供用户名、一个正常的邮箱和密码就可以去邮箱里找确认注册的邮件了。
后来我跟运行这个 Mastodon 实例的朋友 @ShinCurry 交流之后,他抱怨跑一个 Mastodon 就占满了他 VPS 上的内存了。
于是当时我决定去研究 一下Mastodon 背后使用的技术,正好在 Medium 上找到了 Mastodon 开发者,Eugen Rochko 所写的一篇关于扩展 Mastodon 实例的文章,然后顺手翻译了一下。Scaling Mastodon——What it takes to house 43,000 users
在上面引用的这篇 post 中,可以知道 Mastodon 的数据库采用的是纵向扩展,而 Mastodon 自身是横向扩展。也就是说,Mastodon 在设计时只考虑单一数据库的情况,如果数据库成为了你的 Mastodon 实例的瓶颈,那么解决办法就是升级运行数据库的机器的硬件配置。并不是说这样做不好,也不排除官方以后会考虑加入数据库横向扩展的支持。但就目前而言,一方面来说,这样做避免了个人部署者管理多个数据库实例时,配置不妥等原因带来的数据不一致,对于社交平台来说保持数据一致相当重要。另一方面来说,显然的,每增加一个用户,数据库的压力也会随之增加。数据库访问的次数增多,也暗示着用户活动/操作的次数增多,对于前面的 Web 服务器来说压力也增加了。好在 Mastodon 的代码支持在多个主机上并行运行,这样就可以做负载均衡。
监控 Mastodon 实例
了解完 Mastodon 的基础架构之后,我开始了对 Mastodon 官方上的实例列表的监控,大约是每两分钟抓取一次数据。数据的范例如下
[{ connections: 38 https_rank: A+ https_score: 100 ipv6: false name: social.moeoverflow.org openRegistrations: true statuses: 34 up: true uptime: 100 users: 20
}]
然后使用 Splunk 进行分析。对于运营着的 Mastodon 实例来说,比较关心的基本有如下两点。
- 服务可用性(uptime):这里是用的是官方给出的 uptime 数据,这是一个百分数,指最近一段时间内,相应站点的请求成功的的百分比。
- 边界成本:这算是另一个很切实际的问题——比如现在有一个运营着的 Mastodon 实例,当再有一名用户加入时,运营这个 Mastodon 实例所需增加的开销。
第二点非常的现实化,毕竟主机商们可不会太在意你是否要构建一个社交网络,你给这么多钱,就只有这样配置的主机。
分类不同类别的 Mastodon 实例
为了获得一个有意义的调查,在 Splunk 中,分别考虑如下几种情况的 Mastodon 实例。下面的图表先描画服务可用性和用户总的 toots (Mastodon中将用户发的文字称为 toot,在 JSON 数据中对应的是 statuses 字段)数,边界成本将会在下一阶段通过模型解决。以下几种情况并非将所有的 Mastodon 的实例都覆盖,仅仅是个人所做的划分。
- 刚刚起步的 Mastodon 实例:这里假定用户数量(users字段)大于等于 20 人但少于 100 人可视为刚起步的 Mastodon 实例,人数少于这个的有可能还处于调试中,可用性的参考价值不大。
- 小有规模的 Mastodon 实例:这里考虑的除了人数之外,还考虑了与外部 Mastodon 实例连接的数量,也就是上面 JSON 数据中的 connections 字段,先考虑\(30\le connections< 100\)好了,人数在 100 到 200 人间。
- 中型规模的 Mastodon 实例:用户数量在 200 人到 350 之间,外部 Mastodon 连接在 100 到 150 之间。
- 大型规模的 Mastodon 实例:用户数在 350 人以上,外部 Mastodon 连接在 150 以上。
- 刚刚起步的 Mastodon 实例
那么先来看第一种情况,也就是刚刚起步的 Mastodon 实例,它们的平均可用性如下。
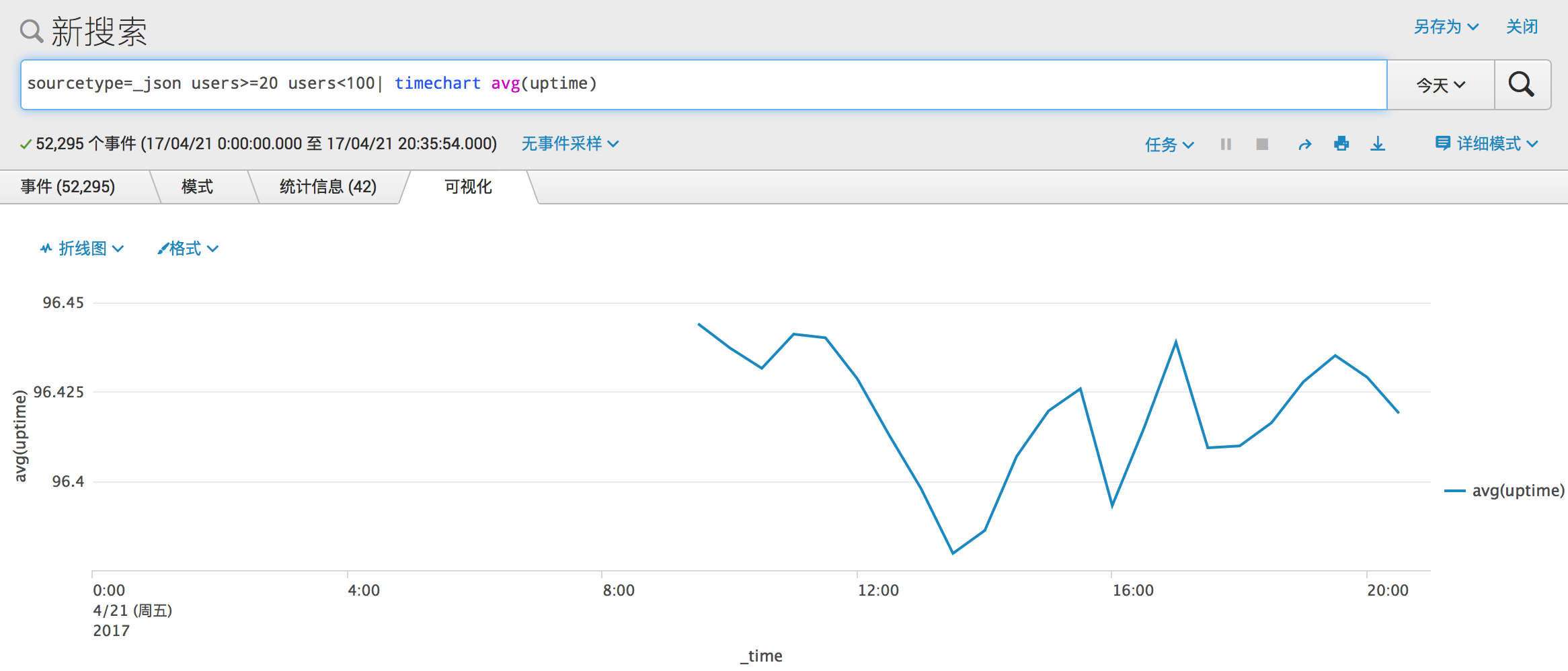
关于这样的折线图,既可以说是平稳保持在 96% 以上,也可以说理解为在 13:30 和 16:00 前后有一批新成长的 Mastodon 实例,所以拖了平均服务可用性。
那么在这些 Mastodon 实例上平均的 toots 数量呢?
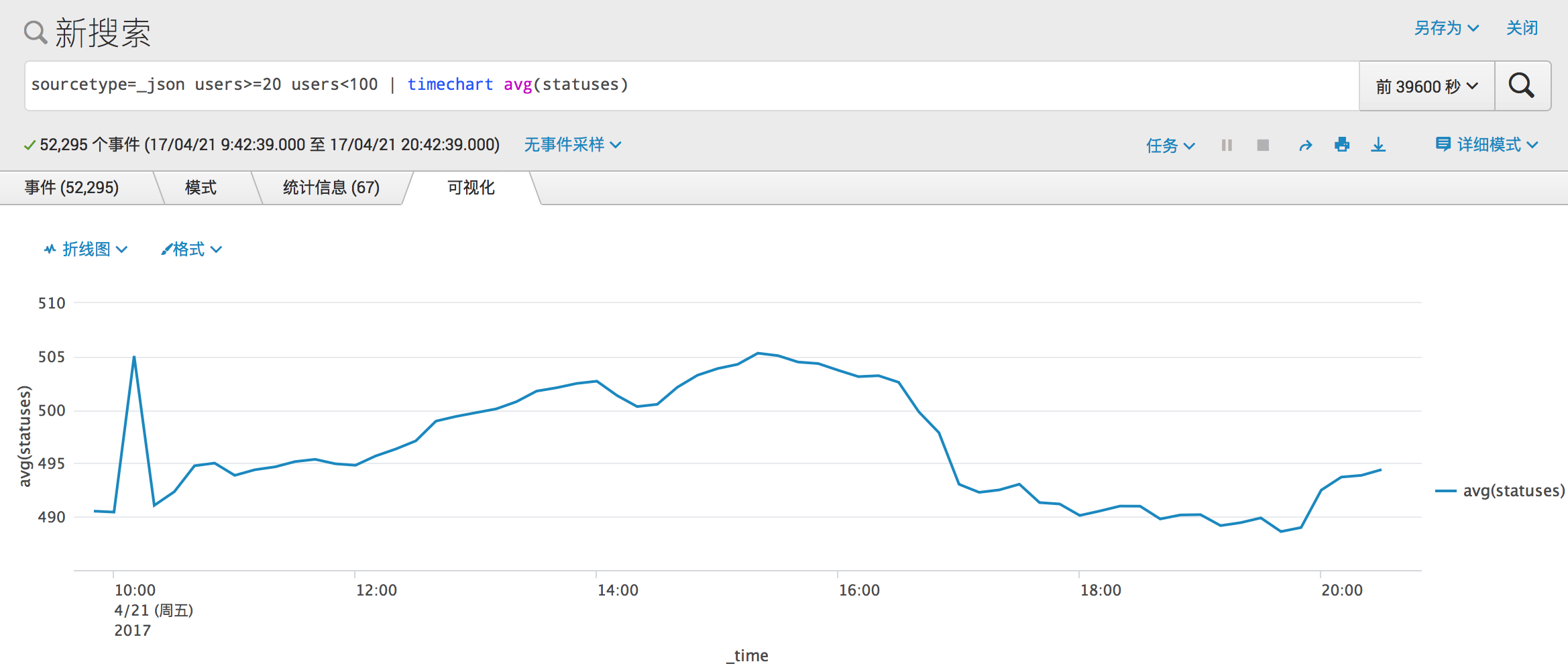
现阶段该类型的每个 Mastodon 实例上有 500 条 toots。
- 小有规模的 Mastodon 实例
将目光投向小有规模的 Mastodon 实例,它们所对应的图像如下。
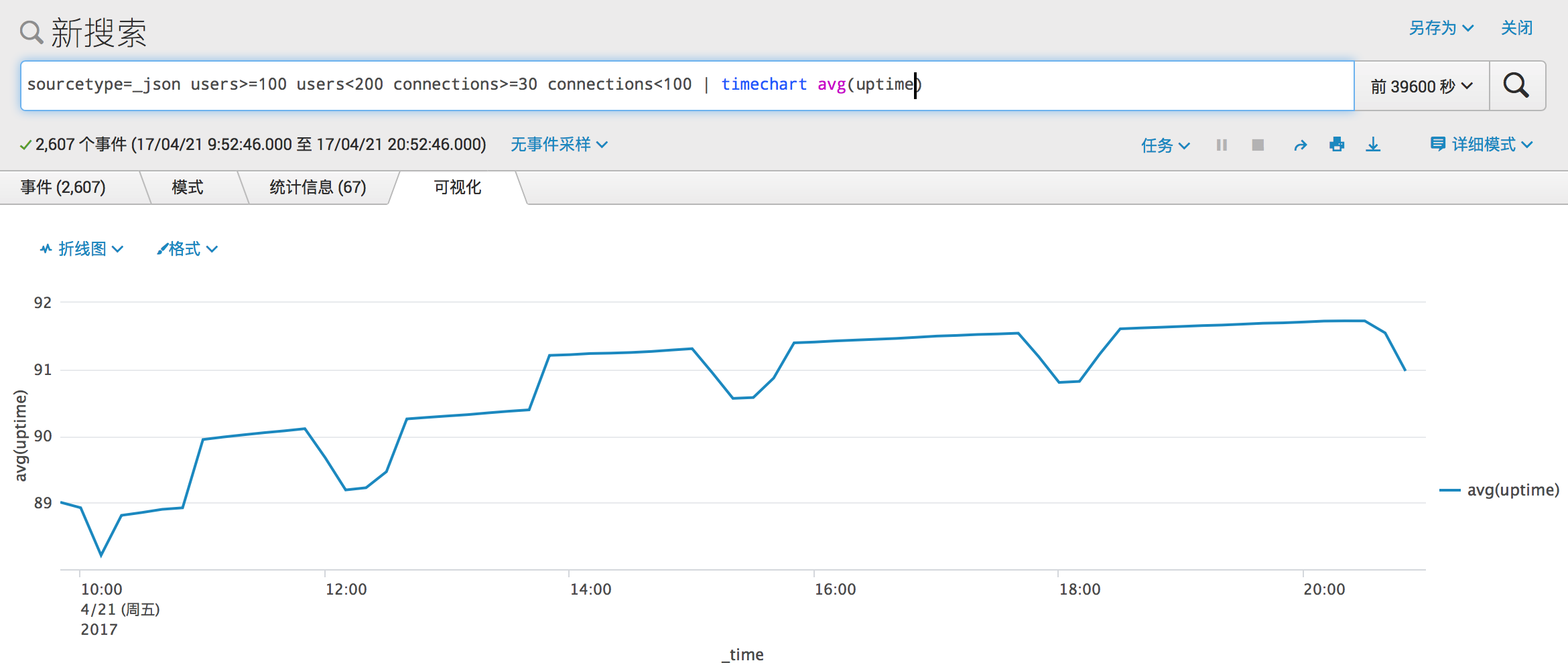
对于小型 Mastodon 实例来说,服务可用性平均在 90% 上下,应该也算是不错的吧,根据图来说,还有上升的走势,但是对比起之前的类型,平均下降了 5% 左右。
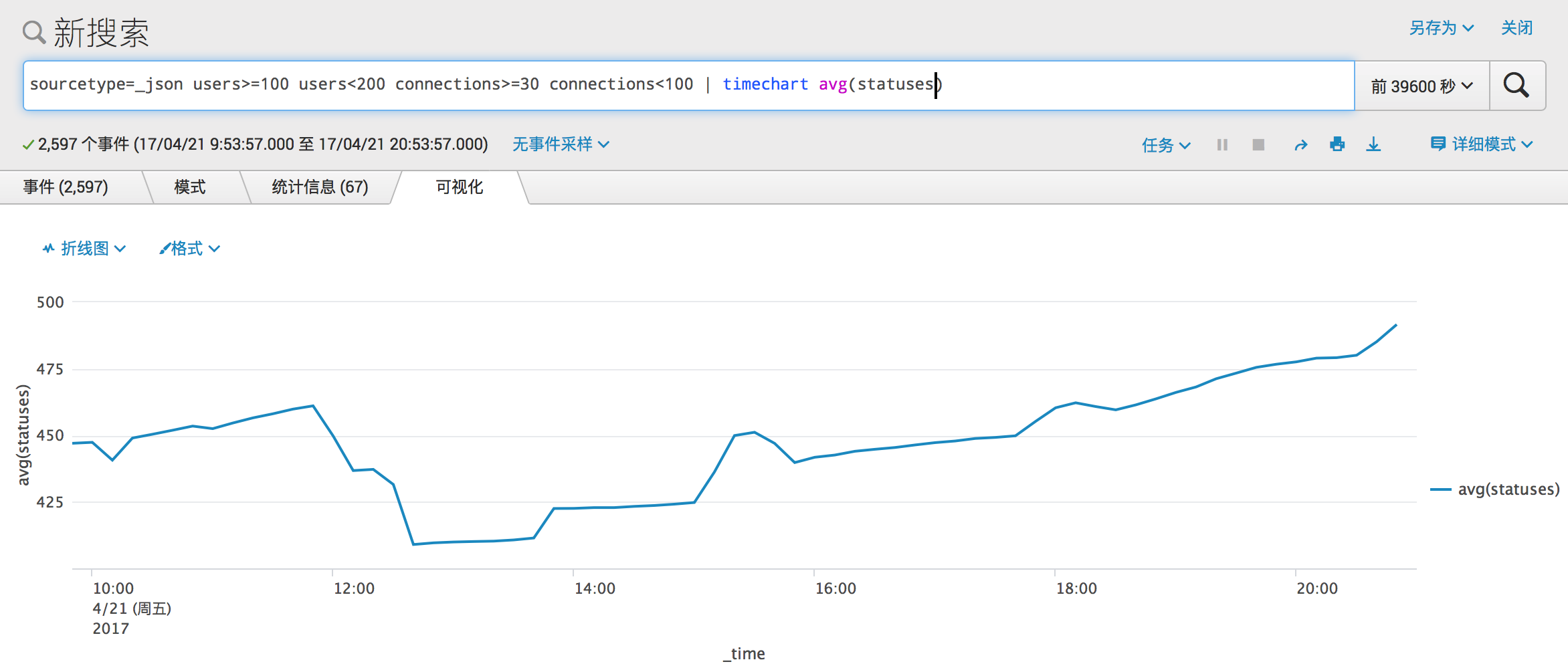
每个 Mastodon 实例上的总 toots 数在 450 上下,有上升趋势。
- 中型规模的 Mastodon 实例
接下来是中型规模的 Mastodon 实例,对应的统计如下。
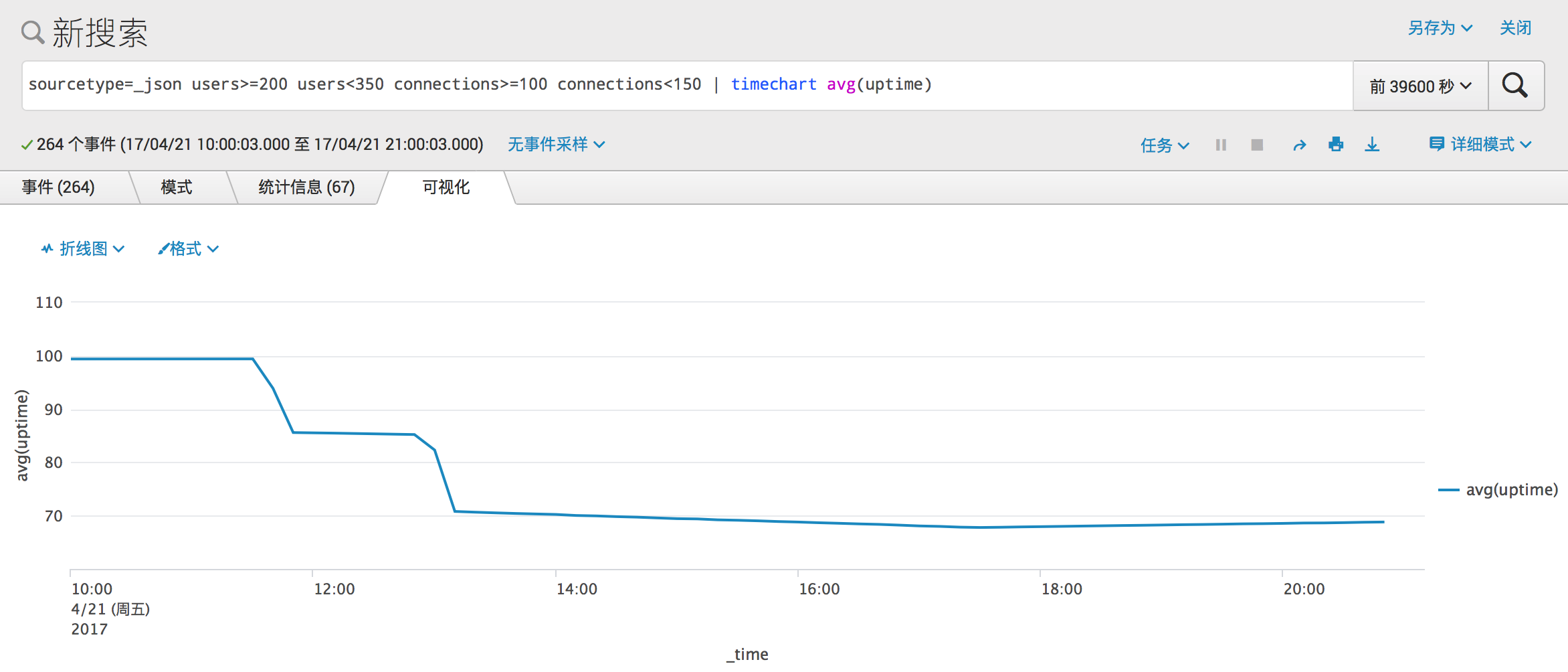
事情到这里开始变得有趣了起来,两个非常明显的台阶,11:50 (UTC +08:00) 和 13:10 (UTC +08:00),中型 Mastodon 实例的服务可用性一路从几乎 100% 下降到了离 70% 还差一点。而下面关于 toots 数的图像提供了一个可能的原因。
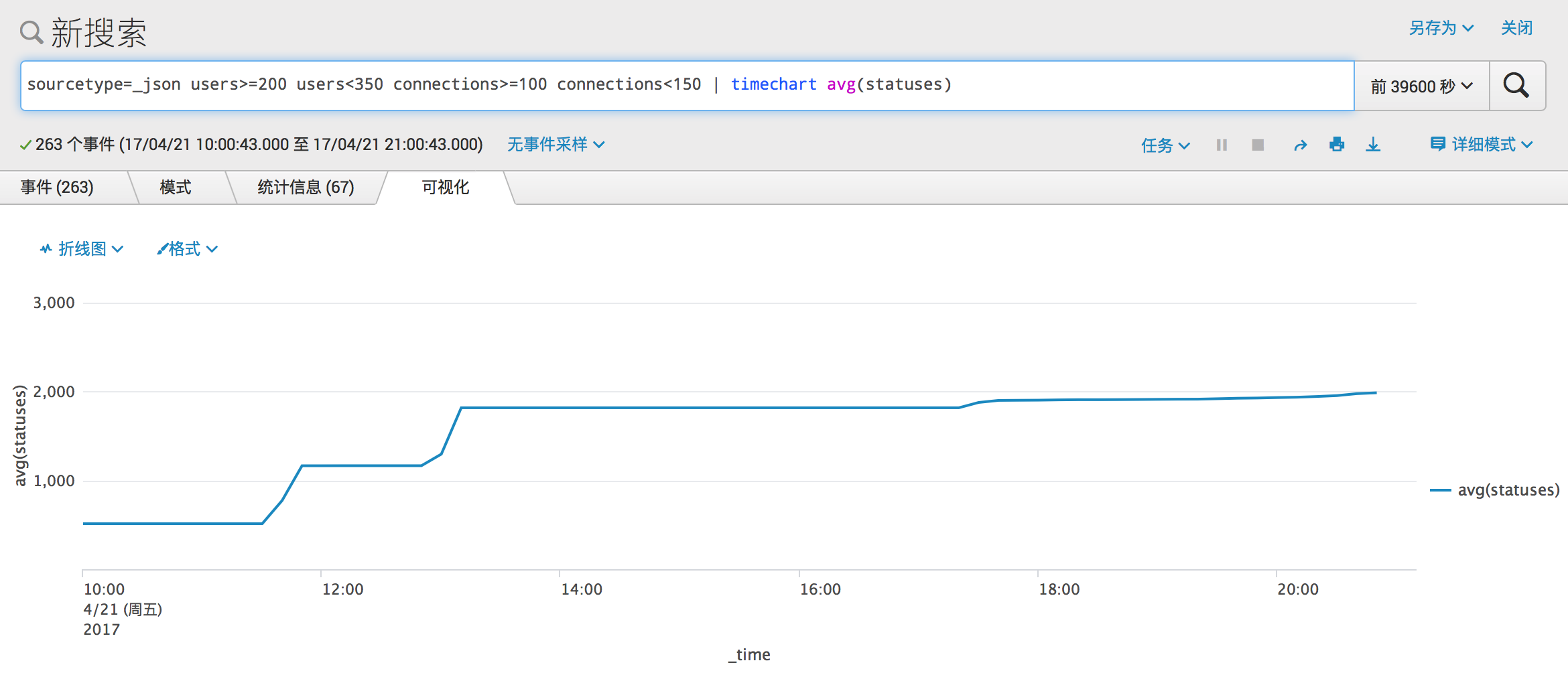
同样是两个较为明显的台阶,时间上基本也与服务可用性变化的台阶对应。当中型 Mastodon 实例中平均 toots 数在 500 上下时,服务可用性逼近 100%,在 11:50 (UTC +08:00) 左右,迎来了第一个台阶,toots 数逐渐上升到 1100 的水平,而平均服务可用性下降到 85%,保持了一段时间后,又迎来了下午 13:10 (UTC +08:00) 的台阶,toots 数达到 1800,而服务可用性进一步下降到 70%。17:30 (UTC +08:00)之后,toots 数又有小幅度的增长,此时服务可用性跌到 70% 一下。
- 大型规模的 Mastodon 实例
最后来看看大型规模的 Mastodon 实例的情况吧。
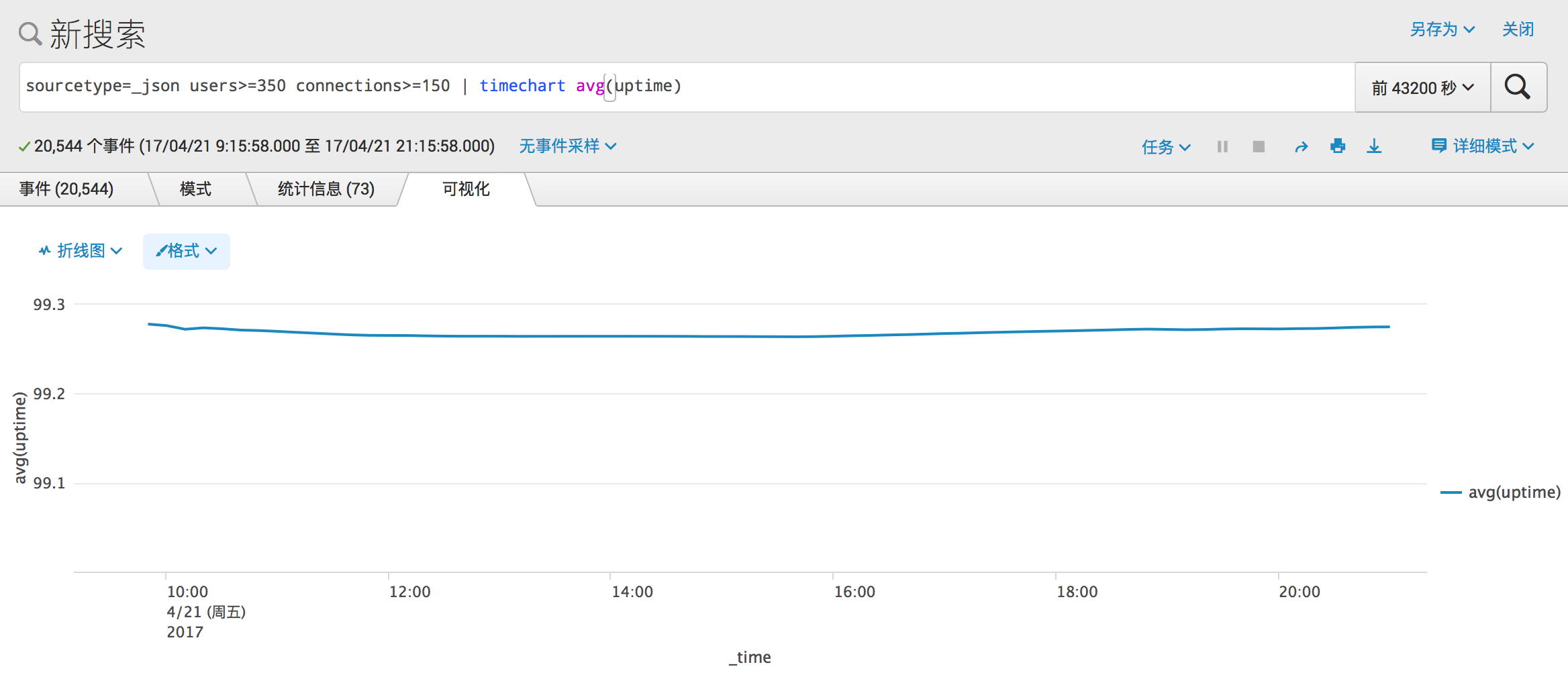
非常平稳的保持在 99.3% 附近。
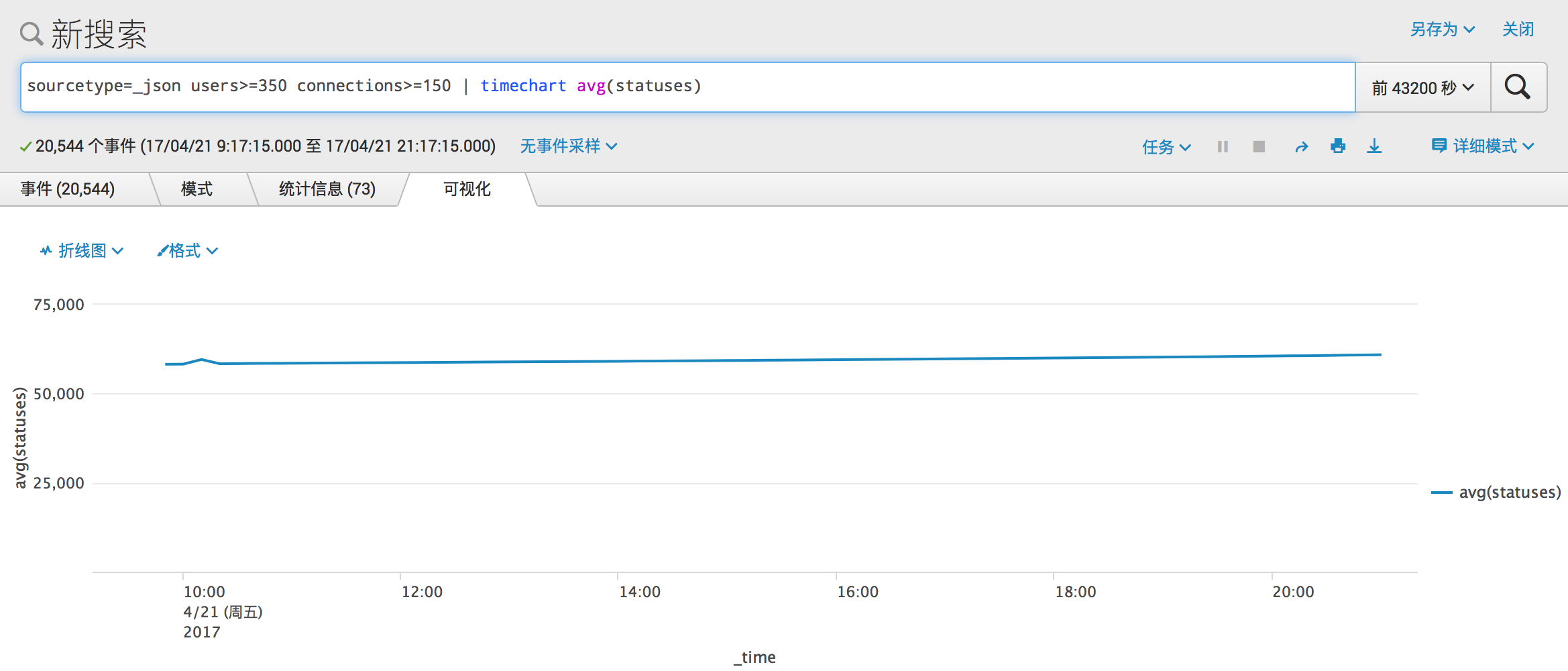
平均 toots 数量非常惊人,早上约是 58,000,截图时的数据已经拆过了 60,000,且还在进一步增长中。但是这些 Mastodon 的服务可用性却非常高。
让我们来看看这些高可用的 Mastodon 实例都是谁吧~这里根据 toots 数量(@17/04/21 21:09 UTC +08:00)列出前10
- mastodon.social,toots 数1369095,第一果然还是官方啊,官方使用的 Mastodon 配置在之前翻译的文章中有提到。
- mstdn.jp,toots 数 1103898
- pawoo.net,toots 数 959586,这个似乎是 pixiv 官方的/官方委托的
- mastodon.cloud,toots 数 308866,
- mastodon.xyz,toots 数 109744,
- witches.town,toots 数 98602,
- mstdn-workers.com,toots 数 87065
- mamot.fr,toots 数 81999
- octodon.social,toots 数 77311
- friends.nico,toots 数 74117,日本弹幕视频网站 niconico 官方运营的 Mastodon 实例
基本可以从名字中看到,这些大型 Mastodon 站点基本是某一个大圈子,背后都是有能力运营大型站点的人,所以他们不仅可以在使用的硬件上保证服务质量,在软实力(技术人员等)上也相当可靠。
为差不多中型规模的 Mastodon 实例建模吧
头疼的大概就是中型规模与逐步靠近中型规模的 Mastodon 实例了吧w
让我们为这些 Mastodon 实例建立一个数学模型试试~
令\(M_1\)表示一个中型规模与逐步靠近中型规模的 Mastodon 实例,\(U(M_1)\)表示在\(M_1\)实例上的注册用户数,其中活跃用户数为\(A(M_1)\),\(T(M_1)\)为\(M_1\)实例上每个活跃用户每月发的 toots 数量的数学期望,\(F_L(M_1)\)为\(M_1\)实例上每个用户的该实例上的关注者(follower)数量的数学期望,\(F_R(M_1)\)对应为\(M_1\)实例上每个用户拥有的在其他实例中的关注者(follower)数量的数学期望。\(C(M_1)\)为该 Mastodon 实例连接到的外部 Mastodon 实例。
那么根据 Mastodon 的规则,
- 每一条 toot 都会分发到本实例中每个关注者的时间线上,这一块由 Default 队列负责;共\(F(M_1)\)个 Default 类别的后台任务
- 接下来是 Push 队列——在 toots 进入 default 队列前,将 toots 送到其他的服务器上——那么这个因素是由用户拥有的在其他实例中的关注者(follower)数量决定;共\(F_R(M_1)\)个 Push 类后台任务
- 由发一条 toot 引发的 Pull / Mailer 任务记为 1
该 Mastodon 实例每个月将会产生\(T(M_1)\times A(M_1)\)条 toots,这些 toots 根据刚才的规则将会产生的任务数总计为
\begin{equation}
\begin{aligned}
&T(M_1)\times A(M_1)\times\\
&(F_L(M_1)+F_R(M_1))
\end{aligned}
\end{equation}
其中,\(T(M_1)\times A(M_1)\times F_R(M_1)\)个 Push 任务就当平均分配给了\(C(M_1)\)个实例上,而本实例也是社交网络中的一部分,因此来自其他 Mastodon 实例所产生的 Push 任务(Push 队列不光是将 toots 送到其他的服务器上,还会处理来自其他服务器的 toots)也将增加\(T(M_1)\times A(M_1)\times F_R(M_1)\)个。因此,最后总计的任务个数为
\begin{equation}
\begin{aligned}
&T(M_1)\times A(M_1)\times\\
&(F_L(M_1)+2F_R(M_1))
\end{aligned}
\end{equation}
负责处理这些任务的是 Sidekiq 进程,在一个常见的 VPS 主机上,大致是双核4线程处理器,若是达到了中型 Mastodon 实例的规模,那么对应的参数分别为
\begin{equation}
\begin{aligned}
U(M_1) &= 300\\
A(M_1) &= 150\\
T(M_1) &= 100\\
F_L(M_1) &= 100\\
F_R(M_1) &= 30\\
C(M_1) &= 100
\end{aligned}
\end{equation}
计算出来的任务总数为
\begin{equation}
\begin{aligned}
&T(M_1)\times A(M_1)\times\\
&(F_L(M_1)+2F_R(M_1))\\
=&100\times 150\times (100 + 2\times 30)\\
=&2,400,000
\end{aligned}
\end{equation}
共计 2,400,000 个后台任务,这还没算上用户浏览页面产生的 HTTP 请求。按照之前提到的“多 worker 少线程”的方案,在双核四线程的主机上启动 4 个 Sidekiq,每个均为 2 线程的话,即使不管这些任务的先后顺序,假设每个任务消耗 100ms(考虑到已经是中型规模的 Mastodon 实例,数据库里应该也有不少记录了),那么处理完这 2,400,000 个任务共需 66 个小时,接近 3 天的时间,也就是一个月里每 10 天就有差不多整整 1 天的高负载时间,换算下来每天则是 2.4 小时的高负载时间。在实际中,这些任务不可能是均匀分布,也就是说,在某段时间内,会遇到性能瓶颈。这一点恰好在中型规模的 Mastodon 实例的 uptime 和 toots 数种体现了出来。
- 边界花费
那么边界花费是多少呢?一个新用户加入所增加的任务数为
\begin{equation}
\begin{aligned}
&T(M_1)\times (F_L(M_1)+2F_R(M_1))\\
=&100\times (100 + 2\times 30)\\
=&16,000
\end{aligned}
\end{equation}
数学期望是增加 16,000 个后台任务(这里还没算上因为新用户的到来关注者数量、数据库存取时间、HTTP请求数量可能产生的变化),而处理这 16,000 个后台任务就已经需要 1,600 秒了。
那么不可避免的,会有越来越多的小型到中型的 Mastodon 实例会面临这样一个选择——升级服务器,或者关闭注册以保证对现有用户的服务。升级服务器的话,显然运营成本增加,无论是个人运营 Mastodon 实例还是有赞助者(个人/商业),这都是一个非常实际的问题,并且如果站点的可用性降低到了某个程度的话,用户的流失也是显然的。这些用户会流向可用性更高的站点,那么对于那些有大赞助者的 Mastodon 实例来说,它们的规模会变得更大,然后利用这些用户群体,获得更多的赞助。
这就是一个社交网络版的人口迁移的模型,每个 Mastodon 实例可以看作是一个城邦,Mastodon 实例的服务水平类似于城邦的吸引力,每个城邦的公民都有自己的评价模式,当现在的城邦不能满足他的要求时,他就会迁移到另一个城邦了。在 Mastodon 中则意味着他不再上那个 Mastodon 站点,转而经常使用另一个。
可以推测,按照现有的 Mastodon 形式,最后很有可能会形成全世界只有一部分大城邦(从现在的 toots 数量上来看,已经有这个趋势了),剩下一些小的城邦(它们要么有着特定的用户,或者忠实的用户,总之会是一个小圈子),还有不少城邦会消失。或许还会产生有不少加入需要收费城邦。
Mastodon 或许会将原来世界里一个巨大的帝国分解,但是按现在的方式,它的结果是产生一部分大型城邦,一部分小圈子城邦。从去中心化的角度来说,它是将一个中心变成了多个主要中心,以及多数零散的点。如果 Mastodon 实例的运营者们持乐观或中立态度的话,那么社交网络在可预见的未来的形态大概就是这样吧,这是 Mastodon 对社交网络作出的回答。
感觉一个压了一年的项目有希望了= =
是什么项目,莫非是写个新的社交网络(#゚Д゚)