嗯,摸鱼的时候看到了一个 C++ 编译时混淆字符串的实现,urShadow/StringObfuscator. (然后还顺便又玩了一下 C++ 模版编程)
怎么说呢,这样的通过C++模版来现实的编译时混淆其实特征还是相对比较明显的,另有一种也是在编译的时候去混淆,但是则是由编译器/编译器插件来现实的。
至于说性能的话,直观来说对于绝大多数日常应用,两种方式相比不做混淆来讲,也没有可观察到的区别。不过我也没去做benchmark,有兴趣的倒是可以一试。
urShadow/StringObfuscator 使用上比较简单,但相比编译器插件的方式,还是会需要对代码做出一定的修改。
#include <iostream> #include "str_obfuscator.hpp" int main(int argc, const char * argv[]) { std::cout << cryptor::create("Hello, World!").decrypt() << std::endl; return 0; }
总的来说实现上很简单,很直接,利用 C++ 模版参数取到要混淆的字符串的长度 S与其本体 str。
template<std::size_t S> static constexpr auto create(const char(&str)[S]) { return string_encryptor<S>{ str, S }; }
随后喂给string_encryptor类;string_encryptor类中包含一个 mutable char _buffer[S],用于保存混淆之后的数据;一个 mutable bool _buffer[S],用于保存混淆之后的数据;以及一个 const char _key,即 XOR 时的另一个运算值(或key)
template<std::size_t S> class string_encryptor { public: // ... private: mutable char _buffer[S]; mutable bool _decrypted; const char _key; };
接下来利用模版匹配递归地对每个字节做 XOR 操作实现混淆的效果,在 urShadow/StringObfuscator 的实现中,XOR 的另一个运算值(或key)为该字符串长度 S % 255. urShadow/StringObfuscator 的实现如下
template<std::size_t index> struct encryptor { static constexpr void encrypt(char *dest, const char *str, char key) { dest[index] = str[index] ^ key; encryptor<index - 1>::encrypt(dest, str, key); } }; template<> struct encryptor<0> { static constexpr void encrypt(char *dest, const char *str, char key) { dest[0] = str[0] ^ key; } };
顺便用 Elixir 玩了一下(不是编译时混淆,就只是写了一下 recursion)
defmodule Sobfs do def do_encrypt([], _key) do [] end def do_encrypt([c | rest], key) do use Bitwise Enum.concat([bxor(c, key)], do_encrypt(rest, key)) end def encrypt(str) do key = str |> List.to_string |> String.length |> rem(255) str |> do_encrypt(key) end end
开 -O2 优化之后在 Hopper 中如下
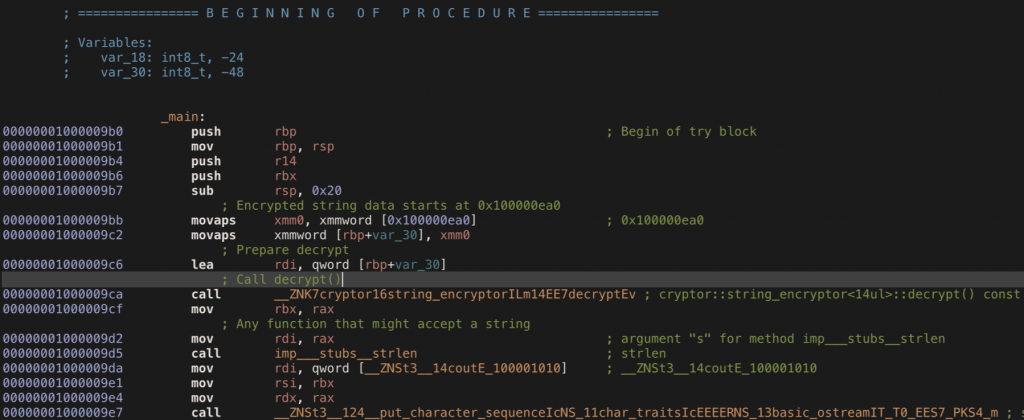
在 strip 掉符号之后,一般来说留意可能接收字符串的函数前面的部分就大致可以猜一猜了。
比如上图里 0x1000009ca 处调用了某一函数,并且该函数的返回值是下面 imp___stubs__strlen 的参数,那么 0x1000009ca 处对应的函数则较有可能是对混淆之后字符串的恢复。
而 0x1000009ca 处对应函数的参数则是 0x1000009bb - 0x1000009c6放入寄存器中的。
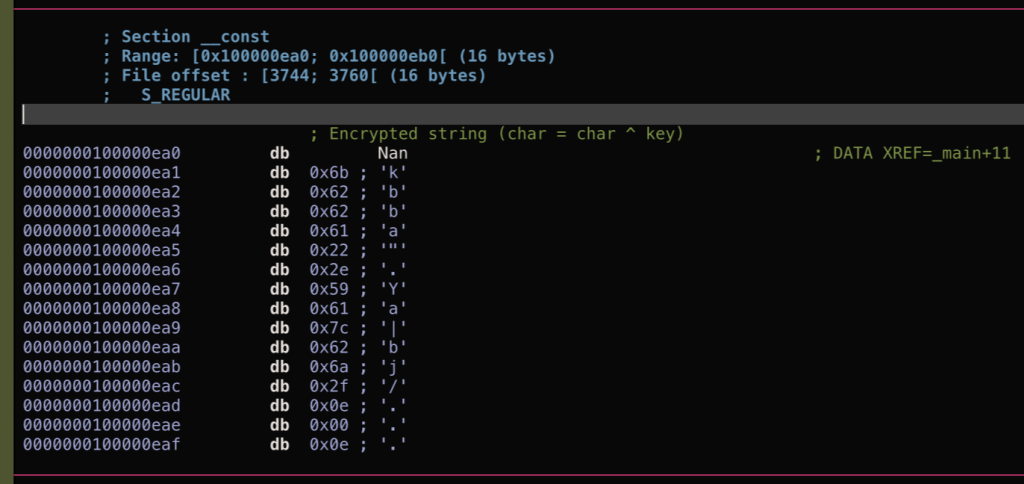
可以看到 0x1000009bb 处加载了 0x100000ea0 处的数据,0x100000ea0 位置上的数据则是
0x1000009ca 处调用的函数则如下,可以看到有大量的 XOR 操作。故而也可以作为一个特征,然后把二进制拿去 disassemble 之后搜索这样成片的 XOR 也能找出来
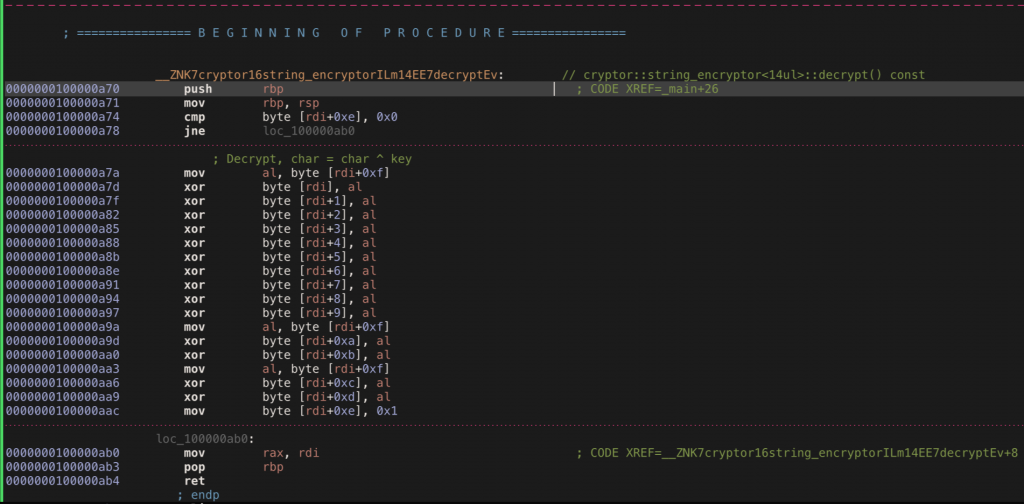
这样的编译时混淆还是很容易看出来的(但是 C++ 的模板编程的确好玩!