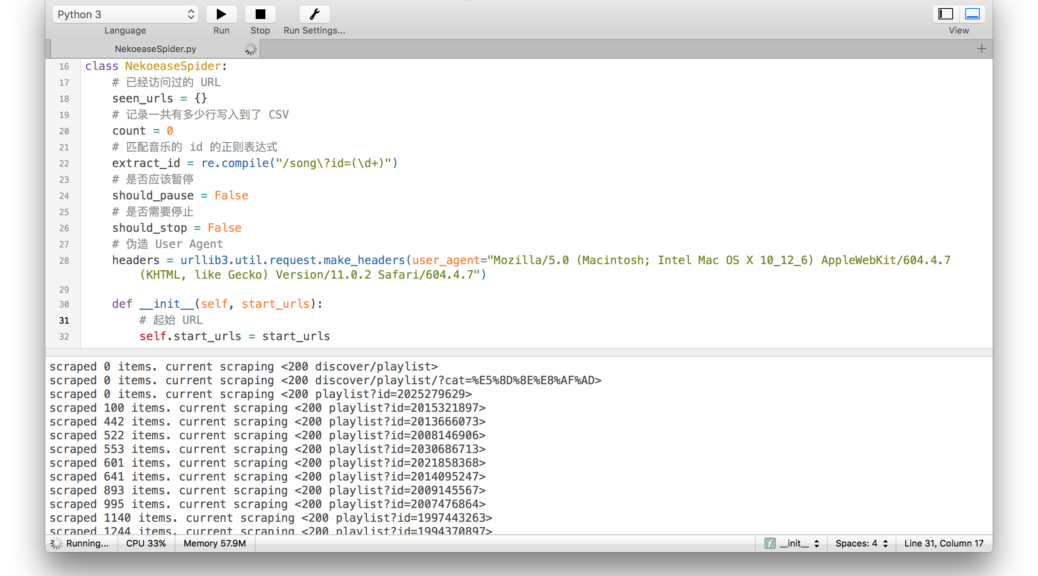
既然想到要写点什么东西的话,那么就来试试网易云音乐吧w
那么第一步,我们要有数据才行,网易也当然不会公开自己的数据库啦,于是我们得用爬虫才行~
Python 语言里可以选择的爬虫还是不少,比如 Scrapy,然后在一开始开开心心的选择了 scrapy,之后发现网易云音乐对于 IP 的访问频率有限制,一旦超过限制,就会触发网易云的保护机制,暂时进入网易云黑名单,此时再访问的话,服务器返回的就都是 HTTP 503 - Service Unavailable。
解决方法说简单也简单,说麻烦也麻烦。简单在于,我的网络是电信的,于是只要重新拨号就能拿到新的公网 IP,写重新拨号的脚本也很简单。而稍有麻烦的地方在于,scrapy 是多线程的,在自己处理网易云返回 503 的时候,要注意重新拨号的脚本只需要执行一次。
如下图所示,假设我们的爬虫是 4 个线程,线程 2 在 t1 时刻访问时,遇到了 HTTP 503 之后,它就会进入我们处理网易云音乐 HTTP 503 的 handler。而对于其他线程来说,如果在 t1 时刻之前就开始访问了的话,那么是没有问题的,比如线程 1;如果是在 t1 时刻之后的话,比如线程 3、4,那么它们也会遇到 HTTP 503,但是这个时候,线程 3、4 就不用再走一次 handler,而是等待然后重试就可以。

但是也不用这么费劲,既然网易云音乐有频率限制,使用多线程的话,反而会更快的触发网易云的黑名单机制,因此,顺便作为重造轮子,我们来自己写个爬虫吧/
我们这里的爬虫的核心只考虑这么一件事,首先需要一个起始链接去抓取,然后 1) 在返回的 HTML 代码中找出我们下一步需要爬取的一堆链接,当然,需要过滤掉已经访问过的 2) 如果这个页面是我们需要提取数据的页面,那么还需要来提取出数据。最后,把提取出来的数据保存起来。
获取网页的话,我们就直接用 requests 吧,然后 HTML 代码的解析使用 BeautifulSoup 和 lxml,保存数据的部分就交给 csv,最后,以防万一,我们需要用 pickle 记录下有哪些 URL 是已经访问过的,这样即使中途出现了之前没有预想到的 Exception 的话,我们重新运行爬虫时也不会丢失进度。
PS. pickle 可以将 Python 里的变量序列化保存在文件里,然后也可以从文件中加载到当前的 Python 程序里。
PPS. 也可以直接跳到完整的代码处~
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from bs4 import BeautifulSoup import csv import lxml import os import pickle import re import requests import signal import sys import urllib3
接下来,我们定义自己的爬虫的类,
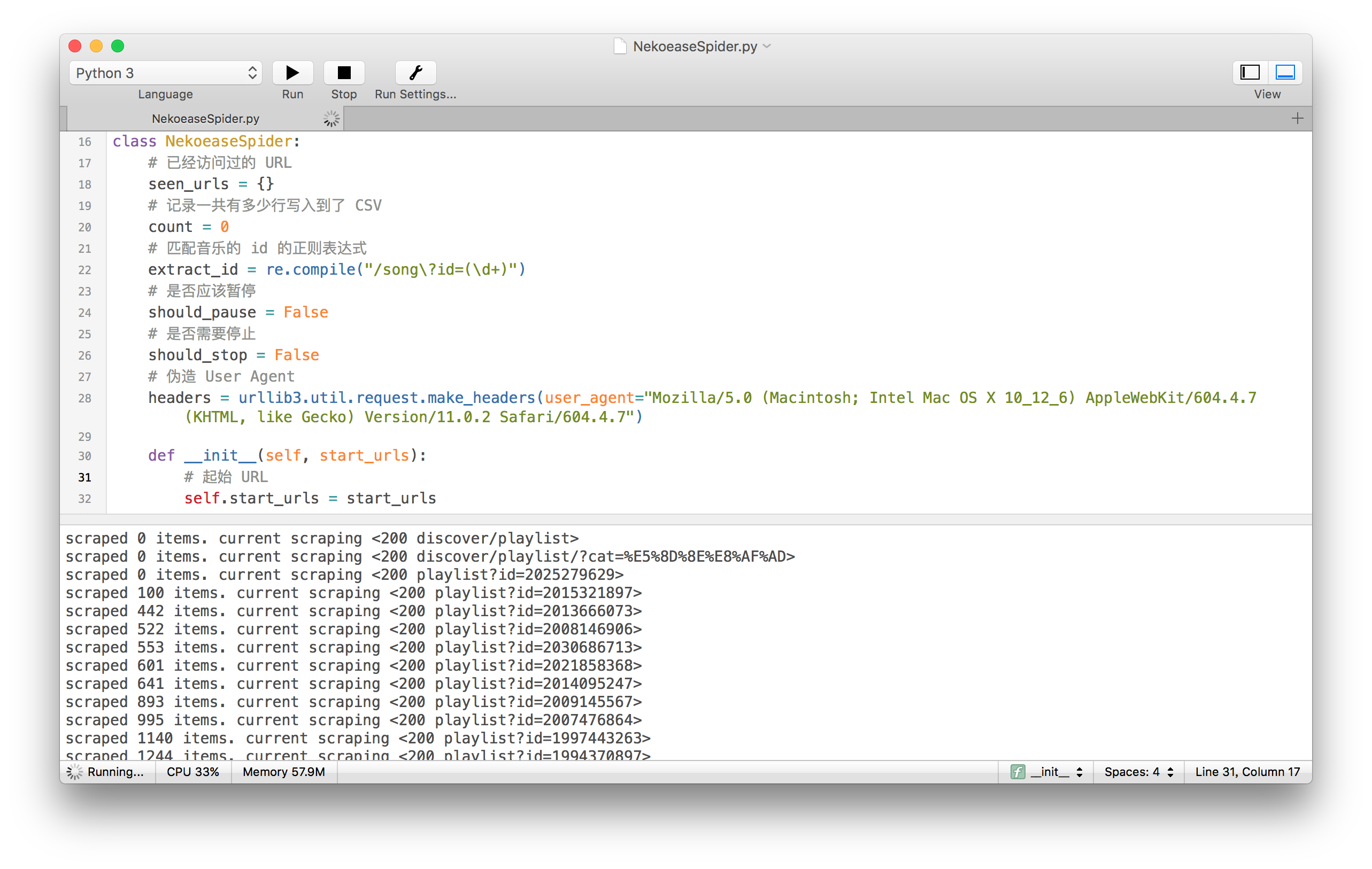
class NekoeaseSpider: # 已经访问过的 URL seen_urls = {} # 记录一共有多少行写入到了 CSV count = 0 # 匹配音乐的 id 的正则表达式 extract_id = re.compile("/song\?id=(\d+)") # # 是否应该暂停 should_pause = False # 是否需要停止 should_stop = False # 伪造 User Agent headers = urllib3.util.request.make_headers(user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7") def __init__(self, start_urls): # 起始 URL self.start_urls = start_urls def run(self): # 如果有 pickle 保存的 seen_urls.plk 文件的话 if os.path.isfile('seen_urls.plk'): # 那么就加载它 with open('seen_urls.plk', 'rb') as f: self.seen_urls = pickle.load(open('seen_urls.plk', 'rb')) # 如果有我们保存的数据了的话 # 就不用再写一次 CSV 的表头 should_write_header = not os.path.isfile('data.csv') # 使用 append 方式打开文件 self.data = open('data.csv', 'a', newline='') # 将打开的文件传给 CSV DictWriter # 我们这里使用的域有三个 # - id, 某首歌在网易云音乐对应的编号 # - title, 歌名 # - tags, 它有哪些标签 self.data_writer = csv.DictWriter(self.data, ['id', 'title', 'tags']) if should_write_header: self.data_writer.writeheader() # 最后,从起始的 URL 开始吧 for url in self.start_urls: self.follow(url, self.parse)
有了这个以后,我们就可以用如下方式调用了
nekoease = NekoeaseSpider(['http://music.163.com/discover/playlist'])
nekoease.run()
现在就去完成 NekoeaseSpider 的 follow 方法吧。follow 方法要做的事也很简单,
1) 先看看当前这个 URL 有没有访问过,没有的话,就去请求页面;否则就不管了
2) 判断请求的状态码是否是 HTTP 200 OK,是的话,就交给 BeautifulSoup,然后调用传进来的 callback;如果请求的状态码是其他的话,就相应处理
3) 根据 callback 的返回类型,如果是 dict 的话,就写到 CSV 里面。
def follow(self, url, callback): # 如果这个 URL 没有访问过 if self.seen_urls.get(url, None) == None: # 那么就跑去请求 response = requests.get(url, headers=self.headers) # 输出 HTTP 相应的值和对应的 URL print("scraped %d items. current scraping <%d%s>" % (self.count, response.status_code, url[21:])) # 如果是 HTTP 200 OK if response.status_code == 200: # 那么这个 URL 就记为访问过 self.seen_urls[url] = True # 用 BeautifulSoup 和 lxml 来解析返回的 HTML soup = BeautifulSoup(response.text, "lxml") # 调用传入的 callback g = callback(soup) try: # 当这个爬虫还没有被要求停下时 # 就一直尝试从 callback 那里要数据 while not self.should_stop: # 如果现在暂停的话 if self.should_pause: # 就等着 continue # 从 callback 那里要数据 result = g.send(None) # 如果是 dict 类型的 if type(result) == dict: # 就写入到 CSV 里面 self.data_writer.writerow(result) # 增加处理的数量 self.count += 1 # 如果 callback 已经完成处理 elif result == "EOP": 那么就从这个 while 里 break 出来 break except: pass elif response.status_code == 503: input("[WARNING] Netease 503. Please change IP!\n")
在有了 follow 方法之后,就差对应的 callback 了,也就是 parse 方法。
现在的话,就需要看网易云音乐的 HTML 代码是怎么组织的了~
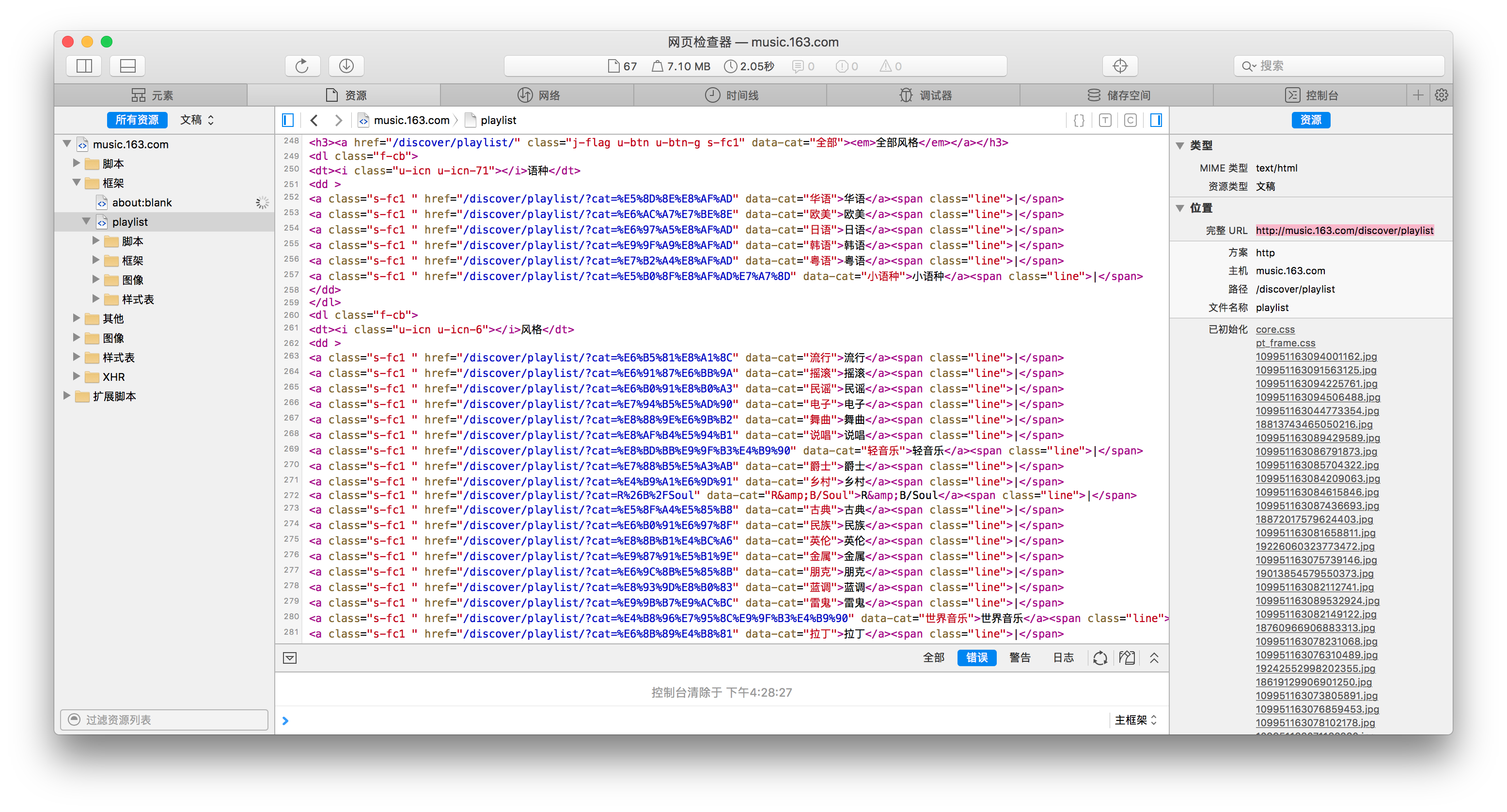
于是能看到这么一堆分类的链接,我们用 xpath 访问就好~
def parse(self, response): # 通过 xpath 选择出刚才上面图中的那些分类的 URL for cat_tag in response.select("dd > a"): # 然后组合成一个完整的 URL,继续跟下去 # 为了简单,我们单独为分类页面的 URL 设置一个 callback 函数 yield self.follow("http://music.163.com%s" % (cat_tag.attrs['href']), self.parse_cat) # 返回 End Of Parse return "EOP"
于是接下来,我们就需要看看分类的页面的 HTML 结构了~以 ACG 分类为例,在这个分类下,对于其中的展示的播放列表,都有如下结构
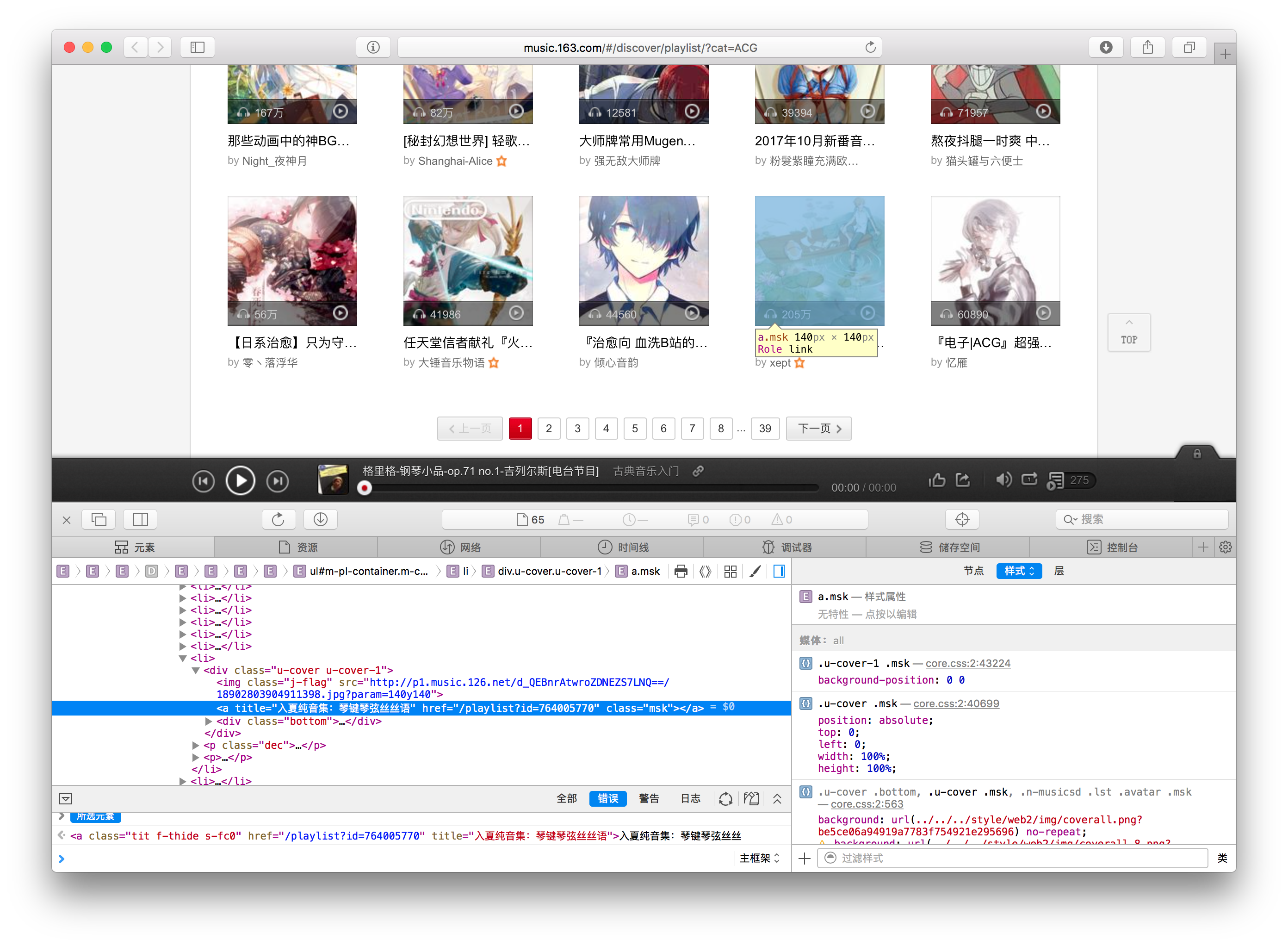
于是这里我们也做类似的 xpath 选择就好~ 在抓取完一页之后,要翻页的话,也是使用 xpath
def parse_cat(self, response): # 当前页面上的 playlist for playlist_tag in response.select("div.u-cover > a"): # 组合成一个完整的 URL,继续跟下去 # 同样的,因为这里点进去是某个具体的播放列表了 # 因此我们单独为具体的播放列表页面设置一个 callback 函数 yield self.follow("http://music.163.com%s" % (playlist_tag.attrs["href"]), self.parse_playlist) # 当上面的 for 循环抓取完这一页的 playlist 之后 # 我们需要看有哪些页码可以去 for page_tag in response.select("div.u-page > a"): page_url = page_tag.attrs['href'] # 这里对页码的 href 稍作判断 # 然后也跟过去 # 由于仍然是某一分类的页面 # 所以 callback 还是 parse_cat if page_url.startswith("/discover"): yield self.follow("http://music.163.com%s" % (page_url), self.parse_cat) # 返回 End Of Parse return "EOP"
最后就来到了处理某一个具体的播放列表了~
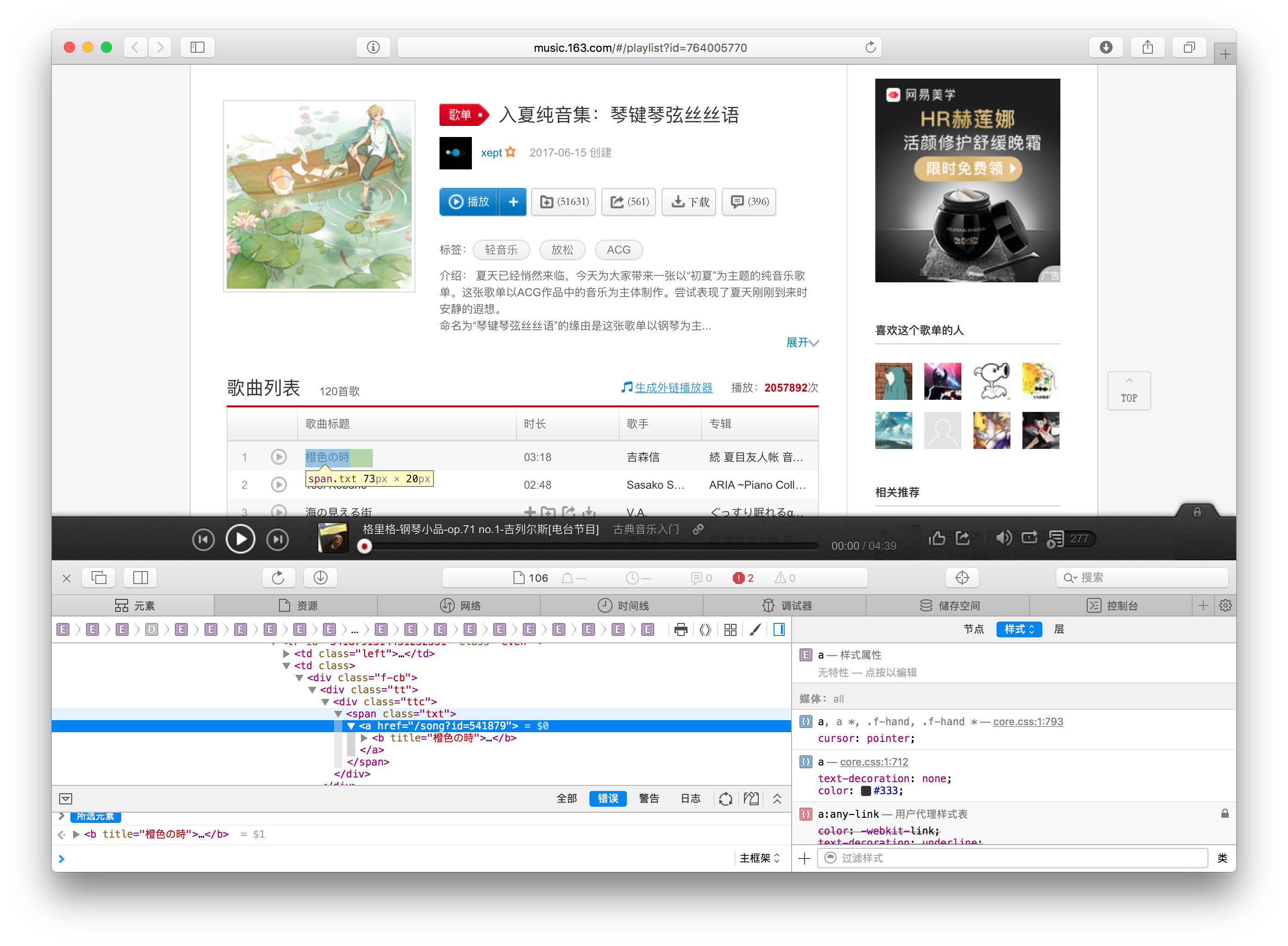
def parse_playlist(self, response): # 记录下这个播放列表的音乐都有哪些标签 cats = [] for cat_tag in response.select("div.tags > a > i"): cats.append(cat_tag.getText()) # 用 | 连接各分类、 # 生成一个字符串 cats_string = "".join(["%s|"% (_) for _ in cats]) cats_string = cats_string[:-1] # 提取出每一首歌 for song_tag in response.select("ul.f-hide > li > a"): # 提取歌的 id song_url = song_tag.attrs["href"] song_id = self.extract_id.match(song_url).group(1) # 歌名 song_title = song_tag.getText() # 返回一个 dict # 它会被写入到我们的 CSV 里面 yield { 'id' : song_id, 'title' : song_title, 'tags' : cats_string } # 返回 End Of Parse return "EOP"
最后,为了方便中途暂停 / 停止,我们加入对 ^C 信号的处理,把这个处理写成 singal_handler 方法
def signal_handler(self, signal, frame): # 如果当前不是暂停状态 if not self.should_pause: # 设置爬虫为暂停 self.should_pause = True # 输出一些统计信息 print("\r[Statictics Info]") print("[%d/%d] items processed" % (len(self.processed_songs), self.count)) print("? Nekoease paused, type q for a fully stop or type c to continue...") while True: # 等待用户输入 # 确认是需要退出还是继续 shoud_continue = input("").strip() # 若要继续 if shoud_continue == "y": # 则重置爬虫的暂停状态 self.should_pause = False # 然后从这个 while 中退出 break # 若是要停止爬虫 elif shoud_continue == "q": print("\r? Nekoease stopped, dumping files...") # 设置爬虫应该停止了 self.should_stop = True # 关闭打开的文件 self.song_cats.close() # 把我们需要的变量用 pickle 保存下来 with open('song-cat-agg-processed.pkl', 'wb') as f: pickle.dump(self.processed_songs, f) print("? Done") # 最后退出整个程序 sys.exit(0)
当然,需要在一开始的时候告诉 Python ^C 由我们来处理了
self.data_writer = csv.DictWriter(self.data, ['id', 'title', 'tags']) if should_write_header: self.data_writer.writeheader() # 让我们来处理 ^C 吧 signal.signal(signal.SIGINT, self.signal_handler) # 最后,从起始的 URL 开始吧 for url in self.start_urls: self.follow(url, self.parse)
最后~完整的代码如下ω
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from bs4 import BeautifulSoup import csv import lxml import os import pickle import re import requests import signal import sys import urllib3 class NekoeaseSpider: # 已经访问过的 URL seen_urls = {} # 记录一共有多少行写入到了 CSV count = 0 # 匹配音乐的 id 的正则表达式 extract_id = re.compile("/song\?id=(\d+)") # # 是否应该暂停 should_pause = False # 是否需要停止 should_stop = False # 伪造 User Agent headers = urllib3.util.request.make_headers(user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7") def __init__(self, start_urls): # 起始 URL self.start_urls = start_urls def run(self): # 如果有 pickle 保存的 seen_urls.plk 文件的话 if os.path.isfile('seen_urls.plk'): # 那么就加载它 with open('seen_urls.plk', 'rb') as f: self.seen_urls = pickle.load(open('seen_urls.plk', 'rb')) # 如果有我们保存的数据了的话 # 就不用再写一次 CSV 的表头 should_write_header = not os.path.isfile('data.csv') # 使用 append 方式打开文件 self.data = open('data.csv', 'a', newline='') # 将打开的文件传给 CSV DictWriter # 我们这里使用的域有三个 # - id, 某首歌在网易云音乐对应的编号 # - title, 歌名 # - tags, 它有哪些标签 self.data_writer = csv.DictWriter(self.data, ['id', 'title', 'tags']) if should_write_header: self.data_writer.writeheader() # 让我们来处理 ^C 吧 signal.signal(signal.SIGINT, self.signal_handler) # 最后,从起始的 URL 开始吧 for url in self.start_urls: self.follow(url, self.parse) def follow(self, url, callback): # 如果这个 URL 没有访问过 if self.seen_urls.get(url, None) == None: # 那么就跑去请求 response = requests.get(url, headers=self.headers) # 输出 HTTP 相应的值和对应的 URL print("scraped %d items. current scraping <%d%s>" % (self.count, response.status_code, url[21:])) # 如果是 HTTP 200 OK if response.status_code == 200: # 那么这个 URL 就记为访问过 self.seen_urls[url] = True # 用 BeautifulSoup 和 lxml 来解析返回的 HTML soup = BeautifulSoup(response.text, "lxml") # 调用传入的 callback g = callback(soup) try: # 当这个爬虫还没有被要求停下时 # 就一直尝试从 callback 那里要数据 while not self.should_stop: # 如果现在暂停的话 if self.should_pause: # 就等着 continue # 从 callback 那里要数据 result = g.send(None) # 如果是 dict 类型的 if type(result) == dict: # 就写入到 CSV 里面 self.data_writer.writerow(result) # 增加处理的数量 self.count += 1 # 如果 callback 已经完成处理 elif result == "EOP": 那么就从这个 while 里 break 出来 break except: pass elif response.status_code == 503: input("[WARNING] Netease 503. Please change IP!\n") def parse(self, response): # 通过 xpath 选择出刚才上面图中的那些分类的 URL for cat_tag in response.select("dd > a"): # 然后组合成一个完整的 URL,继续跟下去 # 为了简单,我们单独为分类页面的 URL 设置一个 callback 函数 yield self.follow("http://music.163.com%s" % (cat_tag.attrs['href']), self.parse_cat) # 返回 End Of Parse return "EOP" def parse_cat(self, response): # 当前页面上的 playlist for playlist_tag in response.select("div.u-cover > a"): # 组合成一个完整的 URL,继续跟下去 # 同样的,因为这里点进去是某个具体的播放列表了 # 因此我们单独为具体的播放列表页面设置一个 callback 函数 yield self.follow("http://music.163.com%s" % (playlist_tag.attrs["href"]), self.parse_playlist) # 当上面的 for 循环抓取完这一页的 playlist 之后 # 我们需要看有哪些页码可以去 for page_tag in response.select("div.u-page > a"): page_url = page_tag.attrs['href'] # 这里对页码的 href 稍作判断 # 然后也跟过去 # 由于仍然是某一分类的页面 # 所以 callback 还是 parse_cat if page_url.startswith("/discover"): yield self.follow("http://music.163.com%s" % (page_url), self.parse_cat) # 返回 End Of Parse return "EOP" def parse_playlist(self, response): # 记录下这个播放列表的音乐都有哪些标签 cats = [] for cat_tag in response.select("div.tags > a > i"): cats.append(cat_tag.getText()) # 用 | 连接各分类、 # 生成一个字符串 cats_string = "".join(["%s|"% (_) for _ in cats]) cats_string = cats_string[:-1] # 提取出每一首歌 for song_tag in response.select("ul.f-hide > li > a"): # 提取歌的 id song_url = song_tag.attrs["href"] song_id = self.extract_id.match(song_url).group(1) # 歌名 song_title = song_tag.getText() # 返回一个 dict # 它会被写入到我们的 CSV 里面 yield { 'id' : song_id, 'title' : song_title, 'tags' : cats_string } # 返回 End Of Parse return "EOP" def signal_handler(self, signal, frame): # 如果当前不是暂停状态 if not self.should_pause: # 设置爬虫为暂停 self.should_pause = True # 输出一些统计信息 print("\r[Statictics Info]") print("[%d/%d] items processed" % (len(self.processed_songs), self.count)) print("? Nekoease paused, type q for a fully stop or type c to continue...") while True: # 等待用户输入 # 确认是需要退出还是继续 shoud_continue = input("").strip() # 若要继续 if shoud_continue == "y": # 则重置爬虫的暂停状态 self.should_pause = False # 然后从这个 while 中退出 break # 若是要停止爬虫 elif shoud_continue == "q": print("\r? Nekoease stopped, dumping files...") # 设置爬虫应该停止了 self.should_stop = True # 关闭打开的文件 self.song_cats.close() # 把我们需要的变量用 pickle 保存下来 with open('song-cat-agg-processed.pkl', 'wb') as f: pickle.dump(self.processed_songs, f) print("? Done") # 最后退出整个程序 sys.exit(0) nekoease = NekoeaseSpider(['http://music.163.com/discover/playlist']) nekoease.run()