论如何正确的使用Dash!(误)
把徳君君的博客放进DocSet吧!(其实就是想看看DocSet到底怎么写而已,才不是想在查API的时候偷看徳君君呢)
DocSet的规范仔细一看还是挺简单的。
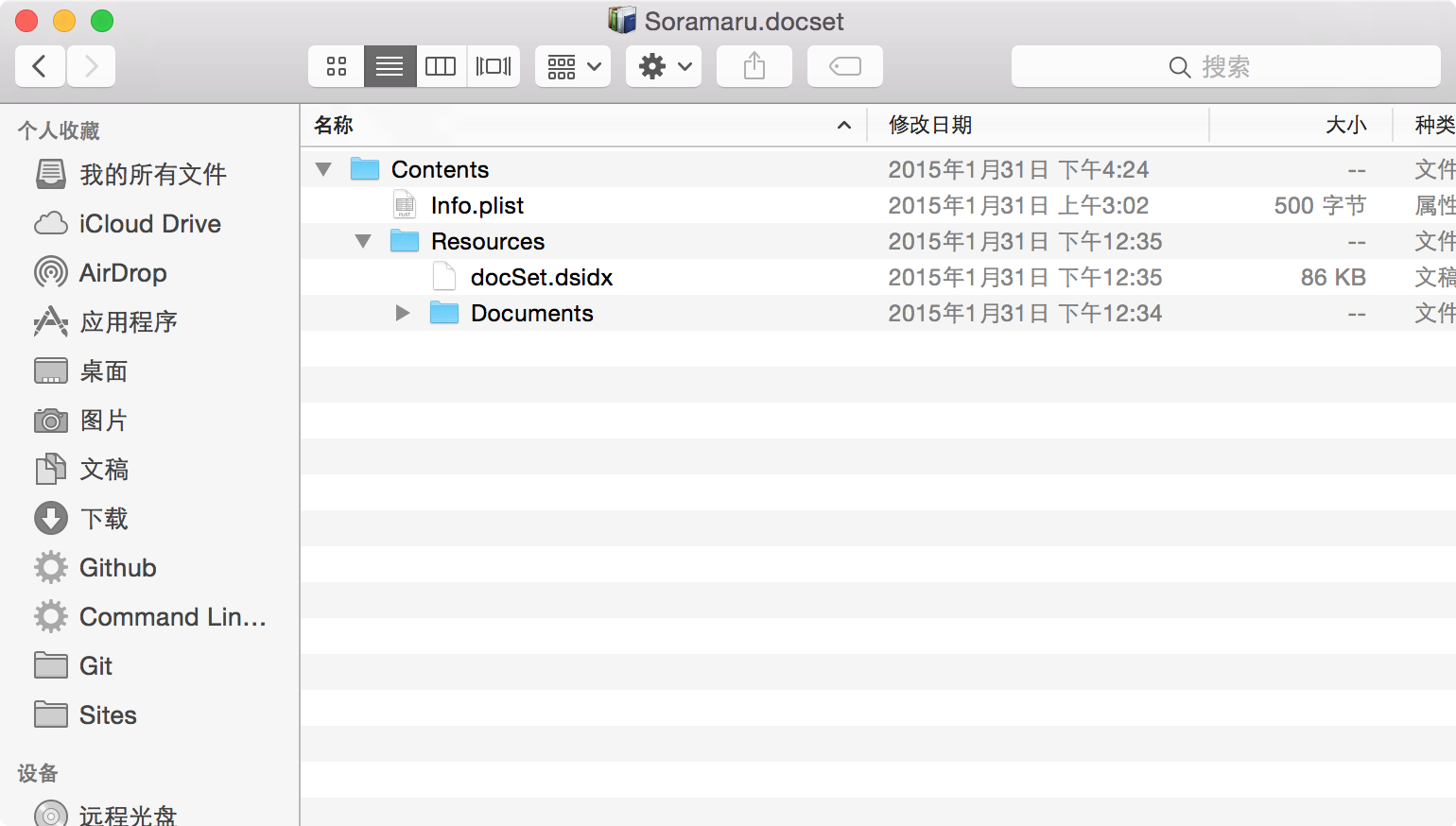
标准的Bundle,既然都贴上图了,那还是还是顺手写一下吧。
先来看看「Info.plist」吧,
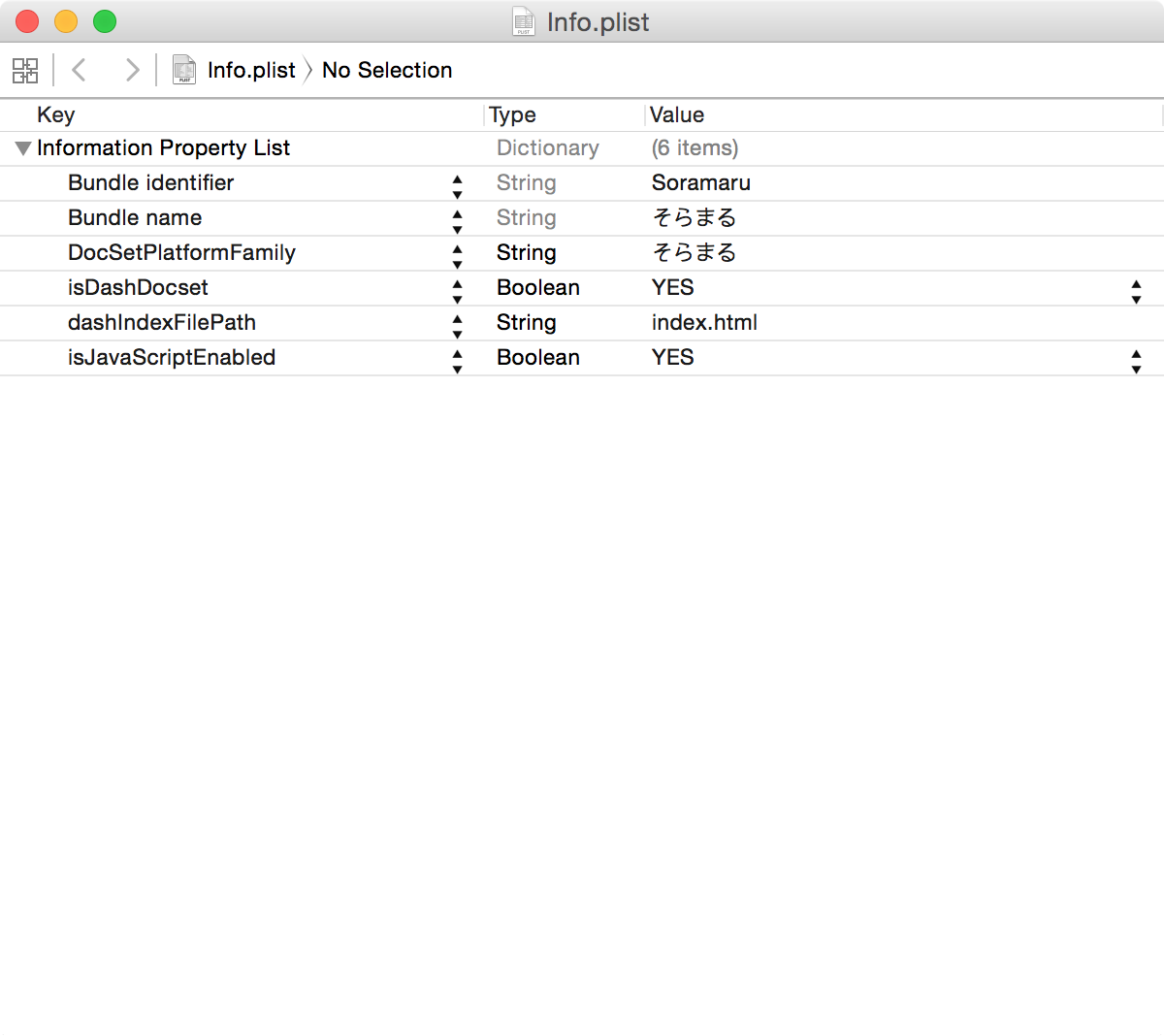
Bundle Name就是会在Dash里面显示的标题。
dashIndexFilePath,这个就是该DocSet默认首页的路径,比如这里的"index.html",实际就应该位于Resources/Documents/index.html
Info.plist里,其他的就是很简单的字面意思了,不提了。
接下来看看docSet.dsidx吧,其实就是个SQLite数据库文件,就一个用于索引的searchIndex表。
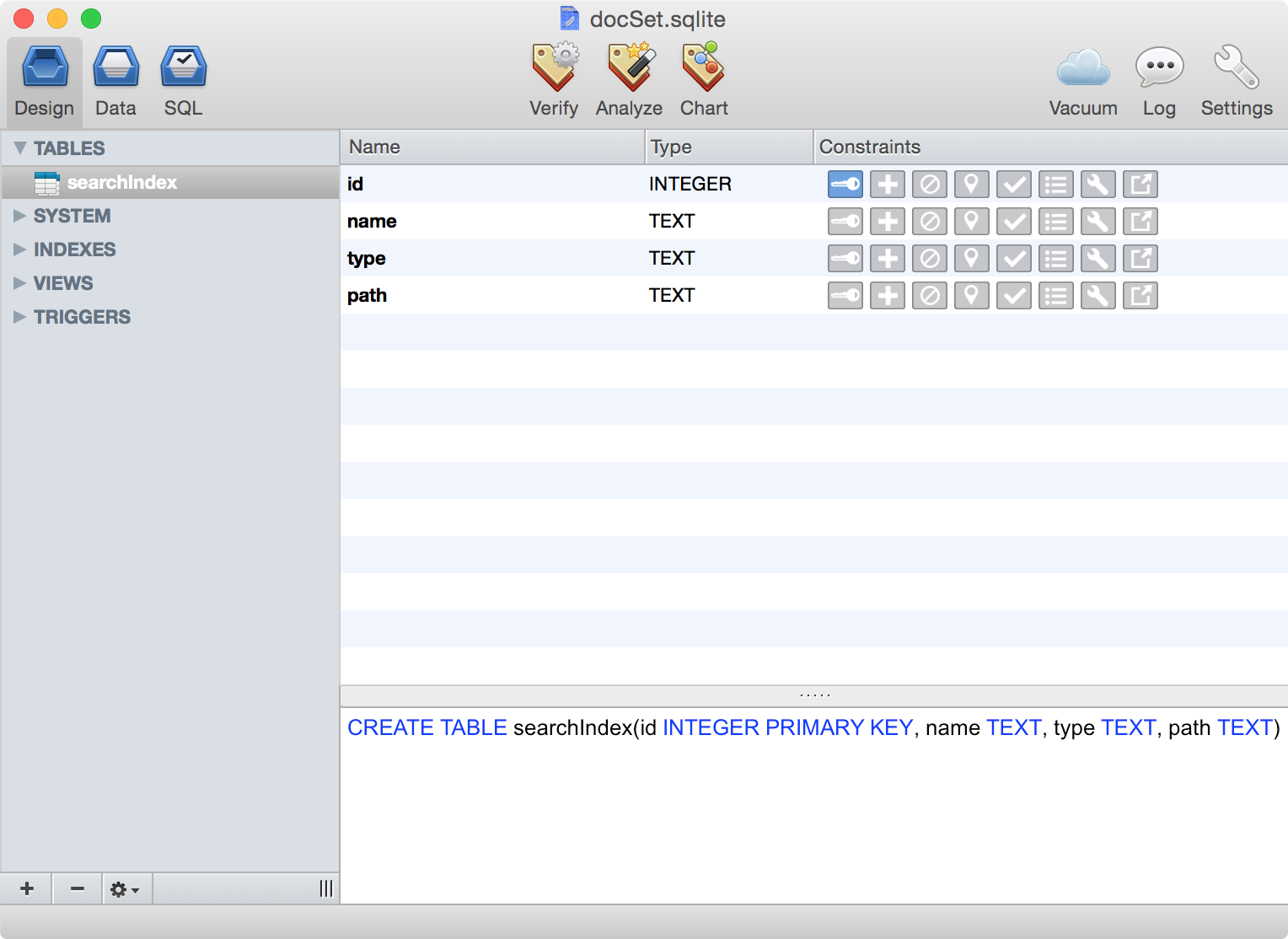
name字段就是显示在Dash中的标题,type字段用于用于表明这一项的类型,而path字段就是对应的html文件路径。
既然知道了这么多,于是先拿徳君君的博客内容。还好是Ameblo上的博客,非常有条理,用一下Xpath查询就可以出来想要的东西,而且在国内访问也不慢。然后写个比较清爽的模版页(其实也是基于bootstrap 3的Sample改的),在Dash里看起来感觉还行。
需要注意的是,一开始想直接用博文的标题作为html的文件名,然后发现这样不行,于是转为了用博文的标题的md5码作为文件名。后来还把上一页和下一页做了,因为Dash那儿体现不出时间。
<?php
$last_title = "#";
for ($i = 1; $i < 218; $i++) {
$dom = new DOMDocument;
@$dom->loadHTMLFile("http://ameblo.jp/tokui-sora/page-$i.html");
$domxpath = new DOMXPath($dom);
$result = new DOMDocument;
$result->formatOutput = true;
$last_title = "#";
for ($i = 1; $i < 218; $i++) {
$dom = new DOMDocument;
@$dom->loadHTMLFile("http://ameblo.jp/tokui-sora/page-$i.html");
$domxpath = new DOMXPath($dom);
$result = new DOMDocument;
$result->formatOutput = true;
// 文章标题
$title = str_replace("n","",$domxpath->query('//h3[@class="title"]')->item(0)->nodeValue);
$title = str_replace("の巻","",$title);
$title = chop($title);
$article_time = str_replace("n","",$domxpath->query('//span[@class="date"]')->item(0)->nodeValue);
// 文章内容
$result->appendChild($result->importNode($domxpath->query('//div[@class="subContentsInner"]')->item(0),true));
$result->normalizeDocument();
$html = $result->saveHTML();
$html = str_replace('subContentsInner','blog-post-content',$html);
$html = str_replace('<!-- google_ad_section_start(name=s1, weight=.9) -->','',$html);
$html = str_replace('<!-- google_ad_section_end(name=s1) -->','',$html);
$html = str_replace('<!--entryBottom-->','',$html);
$html = str_replace("n","",$html);
$template = file_get_contents("template.html");
$template = str_replace('##ARTICLE_TITLE##',$title,$template);
$template = str_replace('##ARTICLE_TIME##',$article_time,$template);
$template = str_replace('##ARTICLE_CONTENT##',$html,$template);
$template = str_replace('##LAST_POST##',$last_title,$template);
file_put_contents(md5($title).".html", $template);
$last_title = md5($title).".html";
print"INSERT INTO searchIndex(name,type,path) VALUES("$title",'Blog','Blog/".md5($title).".html');n";
}
?>
$title = str_replace("の巻","",$title);
$title = chop($title);
$article_time = str_replace("n","",$domxpath->query('//span[@class="date"]')->item(0)->nodeValue);
// 文章内容
$result->appendChild($result->importNode($domxpath->query('//div[@class="subContentsInner"]')->item(0),true));
$result->normalizeDocument();
$html = $result->saveHTML();
$html = str_replace('subContentsInner','blog-post-content',$html);
$html = str_replace('<!-- google_ad_section_start(name=s1, weight=.9) -->','',$html);
$html = str_replace('<!-- google_ad_section_end(name=s1) -->','',$html);
$html = str_replace('<!--entryBottom-->','',$html);
$html = str_replace("n","",$html);
$template = file_get_contents("template.html");
$template = str_replace('##ARTICLE_TITLE##',$title,$template);
$template = str_replace('##ARTICLE_TIME##',$article_time,$template);
$template = str_replace('##ARTICLE_CONTENT##',$html,$template);
$template = str_replace('##LAST_POST##',$last_title,$template);
file_put_contents(md5($title).".html", $template);
$last_title = md5($title).".html";
print"INSERT INTO searchIndex(name,type,path) VALUES("$title",'Blog','Blog/".md5($title).".html');n";
}
?>
然后把执行那一堆SQL,之后再把"Next"按钮的超链接做好。
#!/usr/bin/env perl
use strict;
use warnings;
use utf8;
use 5.010;
use Cwd;
use strict;
use warnings;
use utf8;
use 5.010;
use Cwd;
use File::Spec;
use File::Basename;
use Data::Dumper;
use File::Basename;
use Data::Dumper;
my $cwd = getcwd;
my @files = <*>;
my $file;
my %next;
my @files = <*>;
my $file;
my %next;
foreach $file (@files)
{
my $path = File::Spec->catfile( $cwd, $file );
if ($path =~ /html$/) {
open FIRST, "<$path";
while (<FIRST>) {
if($_ =~ /<a href="(.*)">Previous/){
$next{$1} = basename($path);
}
}
}
}
foreach my $last (keys %next){
open my $out, "./$last";
open OUT, ">script/$last";
print"$lastn";
while (<$out>) {
if ($_ =~ /<a href="(.*)">Next/){
s/"##NEXT_POST##"/"$next{$last}"/g;
print OUT $_;
} else {
print OUT $_;
}
}
}
{
my $path = File::Spec->catfile( $cwd, $file );
if ($path =~ /html$/) {
open FIRST, "<$path";
while (<FIRST>) {
if($_ =~ /<a href="(.*)">Previous/){
$next{$1} = basename($path);
}
}
}
}
foreach my $last (keys %next){
open my $out, "./$last";
open OUT, ">script/$last";
print"$lastn";
while (<$out>) {
if ($_ =~ /<a href="(.*)">Next/){
s/"##NEXT_POST##"/"$next{$last}"/g;
print OUT $_;
} else {
print OUT $_;
}
}
}
本来想把图片也保存下来,但是这样DocSet的Bundle就太大了。
放进Dash里的实际效果~感觉还是可以
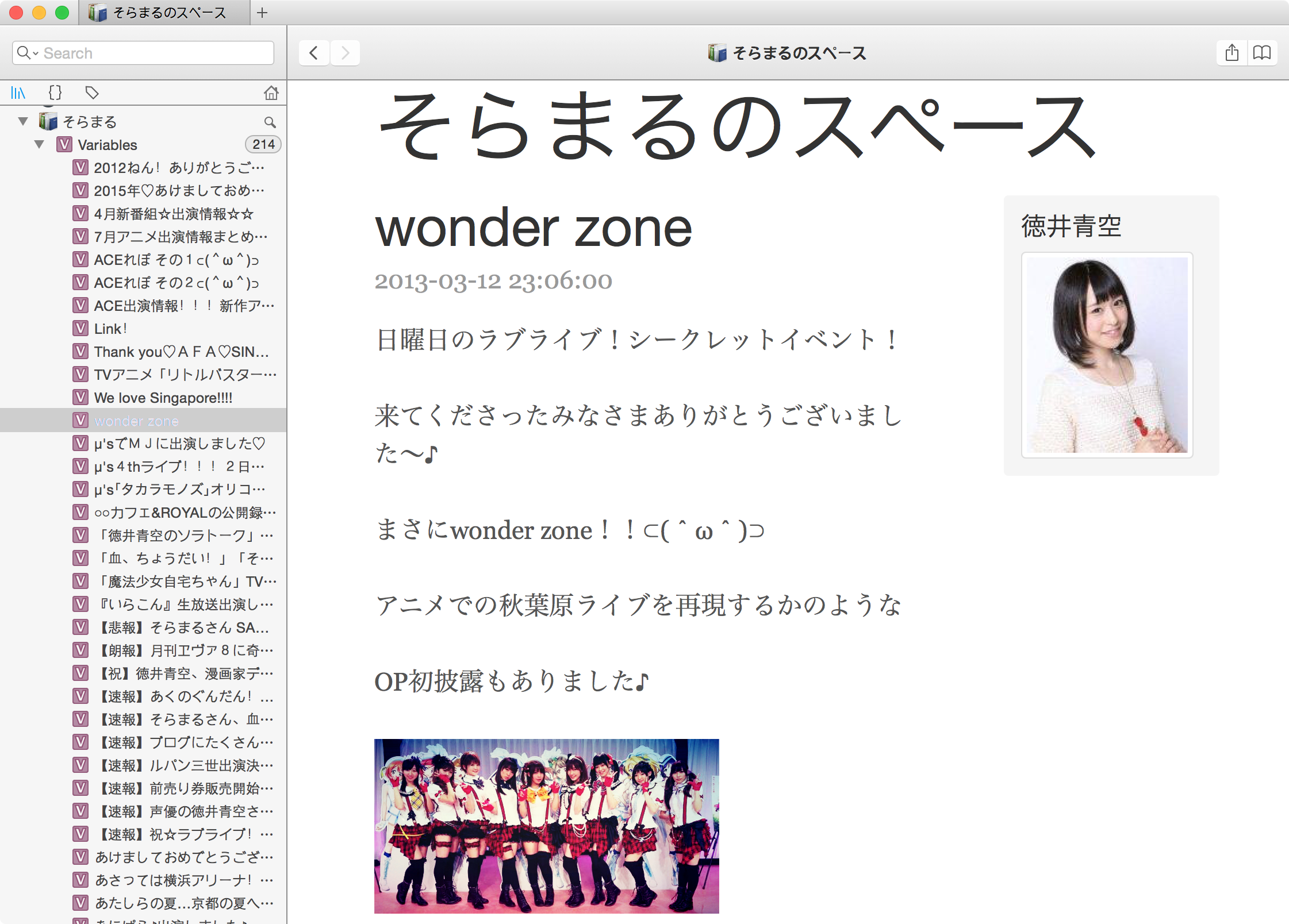
最后我还是把徳君君的DocSet传上来吧。
其实Ameblo的可以搞个自动化的程序来做,哪天有空就来做一下吧。
SQL软件是什么。。
我用的是SQLiteManager,它官网有试用版~